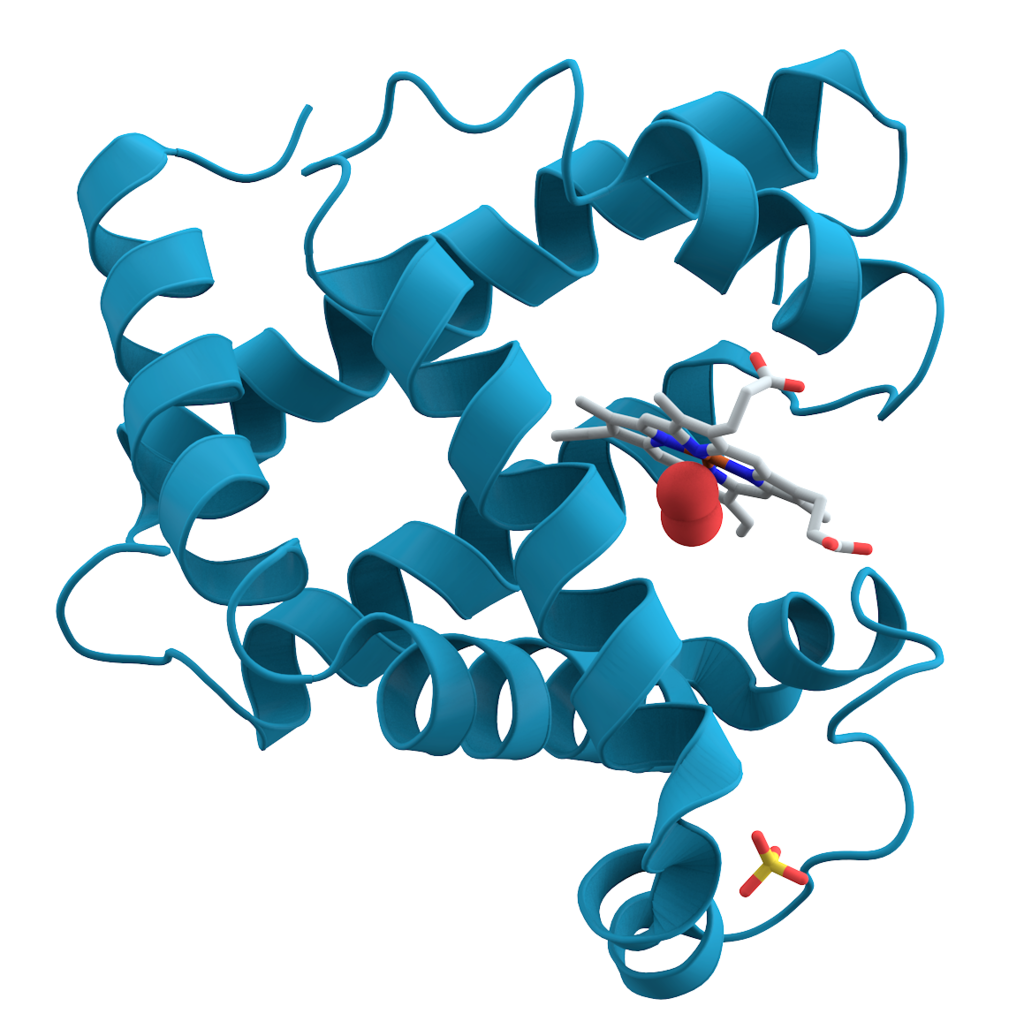5S ribosomal RNA
The 5S ribosomal RNA (5S rRNA) is an approximately 120 nucleotide-long ribosomal RNA molecule with a mass of 40 kDa. It is a structural and functional component of the large subunit of the ribosome in all domains of life (bacteria,archaea, and eukaryotes), with the exception of mitochondrial ribosomes of fungi and animals. The designation 5S refers to the molecule's sedimentation velocity in an ultracentrifuge, which is measured in Svedberg units (S). (W)
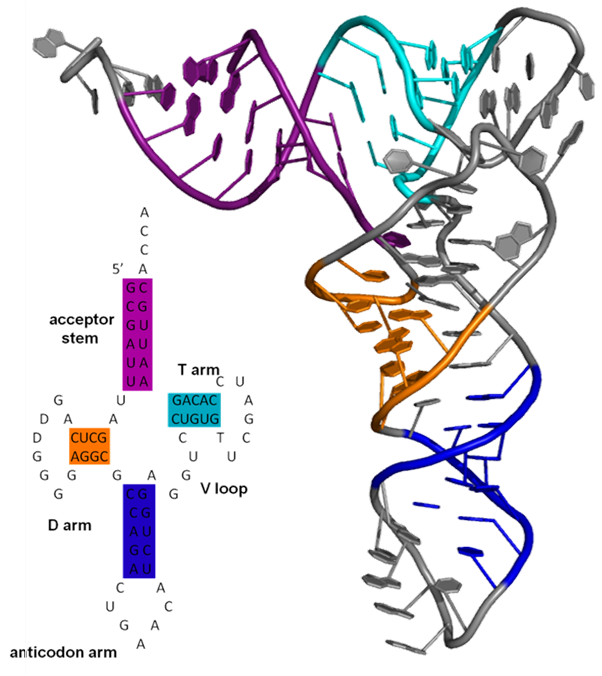
Figure 1: A 3D representation of a 5S rRNA molecule. This structure is of the 5S rRNA from the Escherichia coli 50S ribosomal subunit and is based on a cryo-electron microscopic reconstruction.
Figure 2: Atomic 3D structure of the 50S subunit from Haloarcula marismortui, PDB 1FFK. Proteins are shown in blue, 23S rRNA in orange and 5S rRNA in yellow. 5S rRNA together with the ribosomal proteins L5 and L18 and the domain V of 23S rRNA constitute the bulk of the central protuberance (CP).
Animation of the large subunit of the archaea Haloarcula marismortui. PDB 1FFK.
Figure 3: Consensus secondary structure models of 5S rRNA based on the covariance models used to search for 5S rRNA genes. Models for: A) bacteria, archaea, and eukaryotic nuclei, B) plastids, and C) mitochondria. The IUPAC code letters and circles indicate conserved nucleotides and positions with variable nucleotide identity, respectively. Conserved and covariant substitutions in canonical (Watson-Crick) base-pairs are shaded.
Secondary structure schemes made based on the covariance models used to search for 5S rRNA genes in genomic sequences using the R2R software. .
Figure 4: Comparison of the conventional and permuted secondary structure models of 5S rRNA.
7SK RNA
In molecular biology7SK is an abundant small nuclear RNA found in metazoans. It plays a role in regulating transcription by controlling the positive transcription elongation factor P-TEFb. 7SK is found in a small nuclear ribonucleoprotein complex (snRNP) with a number of other proteins that regulate the stability and function of the complex.(W)
Reversible association of P-TEFb with the 7SK snRNP. P-TEFb is released from the 7SK snRNP by Brd4 or HIV Tat. HEXIM is ejected and the two proteins are replaced by hrRNPs. The reverse of this process requires other unknown factors.
Acetyl-CoA (acetyl coenzyme A) is a molecule that participates in many biochemical reactions in protein, carbohydrate and lipid metabolism. Its main function is to deliver the acetyl group to the citric acid cycle (Krebs cycle) to be oxidized for energy production. Coenzyme A (CoASH or CoA) consists of a β-mercaptoethylamine group linked to the vitamin pantothenic acid (B5) through an amide linkage and 3'-phosphorylated ADP. The acetyl group (indicated in blue in the structural diagram on the right) of acetyl-CoA is linked to the sulfhydryl substituent of the β-mercaptoethylamine group. This thioester linkage is a "high energy" bond, which is particularly reactive. Hydrolysis of the thioester bond is exergonic (−31.5 kJ/mol). (W)
The first category of acids are the proton donors, or Brønsted–Lowry acids. In the special case of aqueous solutions, proton donors form the hydronium ion H3O+ and are known as Arrhenius acids.Brønsted and Lowry generalized the Arrhenius theory to include non-aqueous solvents. A Brønsted or Arrhenius acid usually contains a hydrogen atom bonded to a chemical structure that is still energetically favorable after loss of H+. (W)
Many biologically important molecules are acids. Nucleic acids, which contain acidic phosphate groups, include DNA and RNA. Nucleic acids contain the genetic code that determines many of an organism's characteristics, and is passed from parents to offspring. DNA contains the chemical blueprint for the synthesis of proteins which are made up of amino acid subunits. Cell membranes contain fatty acidesters such as phospholipids.(W)
🛑 ASİT
Asitler suda H iyonu verir; bazlar onu kabul eder.
Sıvı suda su moleküllerinden bir bölümü kendiliğinden hidrojen iyonlarına (H+) ve hidroksid iyonlarına (OH-) ayrılır.
Sıvıda H+ iyonlarının sayısı OH- iyonlarının sayısına eşit olduğu zaman pH 7 ya da nötraldir.
Bazlar H iyonlarını kabul ederek sıvıların pH değerini yükseltir ve onları bazik ya da alkalin (pH 7’nin üzerinde) yaparlar.
Asitler suda çözülünce H iyonlarını verir, ve bu nedenle sıvıların pH değerini düşürerek onları asidik (pH 7’nin altında) yaparlar.
Acetic acid, a weak acid, donates a proton (hydrogen ion, highlighted in green) to water in an equilibrium reaction to give the acetate ion and the hydronium ion. Red: oxygen, black: carbon, white: hydrogen.
acid, organic
An organic acid is an organic compound with acidic properties. The most common organic acids are the carboxylic acids, whose acidity is associated with their carboxyl group –COOH. Sulfonic acids, containing the group –SO2OH, are relatively stronger acids. Alcohols, with –OH, can act as acids but they are usually very weak. The relative stability of the conjugate base of the acid determines its acidity. Other groups can also confer acidity, usually weakly: the thiol group –SH, the enol group, and the phenol group. In biological systems, organic compounds containing these groups are generally referred to as organic acids. (W)
The general structure of a few weak organic acids. From left to right: phenol, enol, alcohol, thiol. The acidic hydrogen in each molecule is colored redext.
The general structure of a few organic acids. From left to right: carboxylic acid, sulfonic acid. The acidic hydrogen in each molecule is colored red.
acid–base reaction
An acid–base reaction is a chemical reaction that occurs between an acid and a base. It can be used to determine pH. Several theoretical frameworks provide alternative conceptions of the reaction mechanisms and their application in solving related problems; these are called the acid–base theories, for example, Brønsted–Lowry acid–base theory.
Their importance becomes apparent in analyzing acid–base reactions for gaseous or liquid species, or when acid or base character may be somewhat less apparent. The first of these concepts was provided by the French chemistAntoine Lavoisier, around 1776.
It is important to think of the acid-base reaction models as theories that complement each other. For example, the current Lewis model has the broadest definition of what an acid and base are, with the Brønsted-Lowry theory being a subset of what acids and bases are, and the Arrhenius theory being the most restrictive.
The reaction of an acid with a base is called a neutralization reaction. The products of this reaction are a salt and water.
Acid Base Reaction Theories as superset and subset models.
Showing Lewis as superset Acid Base Reaction Model with Bronsted-Lowry and Arrhenius as nested subset models that compliment each other as they get more restrictive in their definition.
Water is amphoteric—that is, it can act as both an acid and a base. The Brønsted-Lowry model explains this, showing the dissociation of water into low concentrations of hydronium and hydroxide ions:
Ammonia is a base in the Brønsted-Lowry sense because it acts as a proton acceptor. For example, it accepts a proton from a water molecule to form the ammonium ion and hydroxide ion. In the Lewis Acid-Base theory, the emphasis is on the electron pair. Ammonia is a base because it acts as an electron-pair donor toward the proton. The proton is an acid because it acts as an electron-pair acceptor. Lewis theory is more general than Brønsted-Lowry theory, because it applies to systems that do not involve protons. For example, ammonia acts as an electron-pair donor toward boron tri-fluoride, a molecule that has a vacant 2p orbital. Ammonia also acts as a Lewis base toward metal ions, as in this example of a cobalt 3 hexamine complex. The ammonia electron pairs are donated into vacant metal orbitals. Carbon dioxide acts as a Lewis acid toward water. One of the unshared electron pairs on oxygen is donated to the carbon atom as one of the CO double-bond electron pairs is moved onto the oxygen of carbon dioxide. A proton from the water molecule moves to the oxygen of the carbon dioxide molecule, completing the formation of carbonic acid.
acid dissociation constant
An acid dissociation constant, Ka, (also known as acidity constant, or acid-ionization constant) is a quantitative measure of the strength of an acid in solution. It is the equilibrium constant for a chemical reaction
known as dissociation in the context of acid–base reactions. The chemical species HA is an acid that dissociates into A−, the conjugate base of the acid and a hydrogen ion, H+. The system is said to be in equilibrium when the concentrations of its components will not change over time, because both forward and backward reactions are occurring at the same rate.
The dissociation constant is defined by
where quantities in square brackets represent the concentrations of the species at equilibrium. (W)
In neurons, action potentials play a central role in cell-to-cell communication by providing for—or with regard to saltatory conduction, assisting—the propagation of signals along the neuron's axon toward synaptic boutons situated at the ends of an axon; these signals can then connect with other neurons at synapses, or to motor cells or glands. In other types of cells, their main function is to activate intracellular processes. In muscle cells, for example, an action potential is the first step in the chain of events leading to contraction. In beta cells of the pancreas, they provoke release of insulin. Action potentials in neurons are also known as "nerve impulses" or "spikes", and the temporal sequence of action potentials generated by a neuron is called its "spike train". A neuron that emits an action potential, or nerve impulse, is often said to "fire". (W)
Shape of a typical action potential. The membrane potential remains near a baseline level until at some point in time, it abruptly spikes upward and then rapidly falls.
Shape of a typical action potential. The membrane potential remains near a baseline level until at some point in time, it abruptly spikes upward and then rapidly falls.
As an action potential (nerve impulse) travels down an axon there is a change in polarity across the membrane of the axon. In response to a signal from another neuron, sodium- (Na+) and potassium- (K+) gated ion channels open and close as the membrane reaches its threshold potential. Na+ channels open at the beginning of the action potential, and Na+ moves into the axon, causing depolarization.Repolarization occurs when the K+ channels open and K+ moves out of the axon, creating a change in polarity between the outside of the cell and the inside. The impulse travels down the axon in one direction only, to the axon terminal where it signals other neurons.
Action potential propagation along an axon.
When an action potential arrives at the end of the pre-synaptic axon (top), it causes the release of neurotransmitter molecules that open ion channels in the post-synaptic neuron (bottom). The combined excitatory and inhibitory postsynaptic potentials of such inputs can begin a new action potential in the post-synaptic neuron.
In saltatory conduction, an action potential at one node of Ranvier causes inwards currents that depolarize the membrane at the next node, provoking a new action potential there; the action potential appears to "hop" from node to node.
Ion movement during an action potential. Key: a) Sodium (Na+) ion. b) Potassium (K+) ion. c) Sodium channel. d) Potassium channel. e) Sodium-potassium pump. In the stages of an action potential, the permeability of the membrane of the neuron changes. At the resting state (1), sodium and potassium ions have limited ability to pass through the membrane, and the neuron has a net negative charge inside. Once the action potential is triggered, the depolarization (2) of the neuron activates sodium channels, allowing sodium ions to pass through the cell membrane into the cell, resulting in a net positive charge in the neuron relative to the extracellular fluid. After the action potential peak is reached, the neuron begins repolarization (3), where the sodium channels close and potassium channels open, allowing potassium ions to cross the membrane into the extracellular fluid, returning the membrane potential to a negative value. Finally, there is a refractory period (4), during which the voltage-dependent ion channels are inactivated while the Na+ and K+ ions return to their resting state distributions across the membrane (1), and the neuron is ready to repeat the process for the next action potential.(W)
In chemistry and physics,activation energy is the energy that must be provided to compounds to result in a chemical reaction. The activation energy (Ea) of a reaction is measured in joules per mole (J/mol), kilojoules per mole (kJ/mol) or kilocalories per mole (kcal/mol). Activation energy can be thought of as the magnitude of the potential barrier (sometimes called the energy barrier) separating minima of the potential energy surface pertaining to the initial and final thermodynamic state. For a chemical reaction to proceed at a reasonable rate, the temperature of the system should be high enough such that there exists an appreciable number of molecules with translational energy equal to or greater than the activation energy. The term Activation Energy was introduced in 1889 by the Swedish scientist Svante Arrhenius. (W)
Diagram of a catalytic reaction showing difference in activation energy in uncatalysed and catalysed reaction.
active site
In biology, the active site is the region of an enzyme where substrate molecules bind and undergo a chemical reaction. The active site consists of amino acid residues that form temporary bonds with the substrate (binding site) and residues that catalyse a reaction of that substrate (catalytic site). Although the active site occupies only ~10–20% of the volume of an enzyme, it is the most important part as it directly catalyzes the chemical reaction. It usually consists of three to four amino acids, while other amino acids within the protein are required to maintain the tertiary structure of the enzyme.
Each active site is evolved to be optimised to bind a particular substrate and catalyse a particular reaction, resulting in high specificity. This specificity is determined by the arrangement of amino acids within the active site and the structure of the substrates. Sometimes enzymes also need to bind with some cofactors to fulfil their function. The active site is usually a groove or pocket of the enzyme which can be located in a deep tunnel within the enzyme, or between the interfaces of multimeric enzymes. An active site can catalyse a reaction repeatedly as residues are not altered at the end of the reaction (they may change during the reaction, but are regenerated by the end). This process is achieved by lowering the activation energy of the reaction, so more substrates have enough energy to undergo reaction. (W)
active transport
In cellular biology, active transport is the movement of molecules across a cell membrane from a region of lower concentration to a region of higher concentration—against the concentration gradient. Active transport requires cellular energy to achieve this movement. There are two types of active transport: primary active transport that uses adenosine triphosphate (ATP), and secondary active transport that uses an electrochemical gradient. An example of active transport in human physiology is the uptake of glucose in the intestines. (W)
Example of primary active transport, where energy from hydrolysis of ATP is directly coupled to the movement of a specific substance across a membrane independent of any other species.
Secondary active transport.
In secondary active transport, the required energy is derived from energy stored in the form of concentration differences in a second solute. Typically, the concentration gradient of the second solute was created by primary active transport, and the diffusion of the second solute across the membrane drives secondary active transport.
📹 Active Transport — Sodium-Potassium Exchange Pump 1 / blausen (LINK)
📌 TRANSCRIPTION
n this example, ATP’s energy is harnessed to move sodium ions out of the cell and potassium ions into the cytoplasm. This is the pump that maintains the differences in sodium and potassium ion concentrations between intra- and extra-cellular fluids.
📹 Active Transport Sodium-Potassium Exchange Pump 2 / blausen (LINK)
📌 TRANSCRIPTION
The sodium-potassium exchange pump counteracts these movements; for each molecule of ATP expended by the cell, this exchange pump ejects three sodium ions and reclaims two potassium ions. In this way, the sodium-potassium exchange pump maintains the transmembrane potential and stabilizes the ion composition of the intracellular fluid.
The adjacent image shows pure adenine, as an independent molecule. When connected into DNA, a covalent bond is formed between deoxyribose sugar and the bottom left nitrogen (thereby removing the existing hydrogen atom). The remaining structure is called an adenine residue, as part of a larger molecule. Adenosine is adenine reacted with ribose, as used in RNA and ATP; deoxyadenosine is adenine attached to deoxyribose, as used to form DNA. (W)
🛑 Adenine
DNA’daki dört nükleobazdan biri
(G–C–A–T; Guanin, Sitozin, Adenin ve Thimin).
Ball-and-stick model of the adenosine molecule, a ribonucleoside derived from adenine. Colour code: Carbon, C: black Hydrogen, H: white Oxygen, O: red Nitrogen, N: blue.
Caffeine's principal mode of action is as an antagonist of adenosine receptors in the brain.
adenosine diphosphate
Adenosine diphosphate (ADP), also known as adenosine pyrophosphate (APP), is an important organic compound in metabolism and is essential to the flow of energy in living cells. ADP consists of three important structural components: a sugar backbone attached to adenine and two phosphate groups bonded to the 5 carbon atom of ribose. The diphosphate group of ADP is attached to the 5’ carbon of the sugar backbone, while the adenosine attaches to the 1’ carbon.
ADP can be interconverted to adenosine triphosphate (ATP) and adenosine monophosphate (AMP). ATP contains one more phosphate group than does ADP. AMP contains one fewer phosphate group. Energy transfer used by all living things is a result of dephosphorylation of ATP by enzymes known as ATPases. The cleavage of a phosphate group from ATP results in the coupling of energy to metabolic reactions and a by-product of ADP. ATP is continually reformed from lower-energy species ADP and AMP. The biosynthesis of ATP is achieved throughout processes such as substrate-level phosphorylation,oxidative phosphorylation, and photophosphorylation, all of which facilitate the addition of a phosphate group to ADP. (W)
Skeletal formula of ADP.
Ball-and-stick model of ADP (shown here as a 3- ion).
AMP plays an important role in many cellular metabolic processes, being interconverted to ADP and/or ATP. AMP is also a component in the synthesis of RNA.(W)
The adenosine receptors are commonly known for their antagonists caffeine and theophylline, whose action on the receptors produces the stimulating effects of coffee,tea and chocolate.(W)
Caffeine keeps you awake by blocking adenosine receptors.
Simplified illustration of extracellular purinergic signalling. A schematic representation of the elements involved in the release of ATP by opening of Panx-1 hemichannels and subsequent activation of purinergic signaling. Pathological or physiological stimuli result in the opening of Panx-1 hemichannels promoting the release of ATP from the cell. ATP/ADP/AMP could then bind to P2X and P2Y receptors. Ecto-nucleoside triphosphate diphosphydrolase (E-NTDPase) including ecto-ATPase and ATP-diphospho-hydrolase promotes the hydrolysis of ATP to ADP or from ADP to AMP (2). Ecto-nucleotide pyrophosphatase/phosphodiesterase (E-NPP) hydrolysis ATP to AMP (1). AMP is further hydrolyzed by Ecto-5'-nucleotidase/ CD73 (3) which promotes the formation of adenosine. Adenosine then activates adenosine receptors (AR). (LINK)
adenosine triphosphate (ATP)
Adenosine triphosphate (ATP) is an organic compound that provides energy to drive many processes in living cells, e.g. muscle contraction, nerve impulse propagation, and chemical synthesis. Found in all known forms of life, ATP is often referred to as the "molecular unit of currency" of intracellular energy transfer. When consumed in metabolic processes, it converts either to adenosine diphosphate (ADP) or to adenosine monophosphate (AMP). Other processes regenerate ATP so that the human body recycles its own body weight equivalent in ATP each day. It is also a precursor to DNA and RNA, and is used as a coenzyme.
Structure of adenosine triphosphate (ATP), protonated. Animation (LINK)
adherens junction
Adherens junctions (or zonula adherens, intermediate junction, or "belt desmosome") are protein complexes that occur at cell–cell junctions in epithelial and endothelial tissues, usually more basal than tight junctions. An adherens junction is defined as a cell junction whose cytoplasmic face is linked to the actin cytoskeleton. They can appear as bands encircling the cell (zonula adherens) or as spots of attachment to the extracellular matrix (adhesion plaques). Adherens junctions uniquely disassemble in uterine epithelial cells to allow the blastocyst to penetrate between epithelial cells.
A similar cell junction in non-epithelial, non-endothelial cells is the fascia adherens. It is structurally the same, but appears in ribbonlike patterns that do not completely encircle the cells. One example is in cardiomyocytes. (W)
The diagram shows a cell-cell junction called adherens or zonula adherens. It also contains the main proteins involved in it.
Principal interactions of structural proteins at cadherin-based adherens junction. Actin filaments are associated with adherens junctions in addition to several other actin-binding proteins such as vinculin. The head domain of vinculin associates to E-cadherin via α-, β - and γ -catenins. The tail domain of vinculin binds to membrane lipids and to actin filaments.
alcohol
In chemistry,alcohol is an organic compound that carries at least one hydroxylfunctional group (−OH) bound to a saturatedcarbon atom. The term alcohol originally referred to the primary alcohol ethanol (ethyl alcohol), which is used as a drug and is the main alcohol present in alcoholic beverages. An important class of alcohols, of which methanol and ethanol are the simplest members, includes all compounds for which the general formula is CnH2n+1OH. Simple monoalcohols that are the subject of this article include primary (RCH2OH), secondary (R2CHOH) and tertiary (R3COH) alcohols.
The suffix -ol appears in the IUPAC chemical name of all substances where the hydroxyl group is the functional group with the highest priority. When a higher priority group is present in the compound, the prefix hydroxy- is used in its IUPAC name. The suffix -ol in non-IUPAC names (such as paracetamol or cholesterol) also typically indicates that the substance is an alcohol. However, many substances that contain hydroxyl functional groups (particularly sugars, such as glucose and sucrose) have names which include neither the suffix -ol, nor the prefix hydroxy-. (W)
Ball-and-stick model of an alcohol molecule (R3COH). The red and grey balls represent the hydroxyl group (-OH). The three "R's" stand for carbon substituents or hydrogen atoms.
The bond angle between an hydroxyl group (-OH) and a chain of carbon atoms (R).
aldehyde
An aldehyde is a compound containing a functional group with the structure −CHO, consisting of a carbonyl center (a carbon double-bonded to oxygen) with the carbon atom also bonded to hydrogen and to an R group, which is any generic alkyl or side chain. The group—without R—is the aldehyde group, also known as the formyl group. Aldehydes are common in organic chemistry, and many fragrances are or contain aldehydes.(W)
These are the two-dimensional chemical structures of important aldehydes. The aldehyde group is colored red. The structures are labeled with numbers (1 through 8) as follows... formaldehyde formaldehyde's trimer, 1,3,5-trioxane [chair conformation] acetaldehyde acetaldehyde's enol, vinyl alcohol α-D-glucopyranose [chair conformation] cinnamaldehyde retinal pyridoxal.
aldose
An aldose is a monosaccharide (a simple sugar) with a carbon backbone chain with a carbonyl group on the endmost carbon atom, making it an aldehyde, and hydroxyl groups connected to all the other carbon atoms. Aldoses can be distinguished from ketoses, which have the carbonyl group away from the end of the molecule, and are therefore ketones.(W)
In chemistry, an alkali (from Arabic:القلوي al-qaly "ashes of the saltwort") is a basic,ionicsalt of an alkali metal or alkaline earth metalchemical element.An alkali also can be defined as a base that dissolves in water.A solution of a soluble base has a pH greater than 7.0. The adjectivealkaline is commonly, and alkalescent less often, used in English as a synonym for basic, especially for bases soluble in water. This broad use of the term is likely to have come about because alkalis were the first bases known to obey the Arrhenius definition of a base, and they are still among the most common bases.
Common properties of alkalis and bases
Alkalis are all Arrhenius bases, ones which form hydroxide ions (OH-) when dissolved in water. Common properties of alkaline aqueous solutions include:
Moderately concentrated solutions (over 10-3 M) have a pH of 7.1 or greater. This means that they will turn phenolphthalein from colorless to pink.
Concentrated solutions are caustic (causing chemical burns).
Alkaline solutions are slippery or soapy to the touch, due to the saponification of the fatty substances on the surface of the skin.
Alkalis are normally water-soluble, although some like barium carbonate are only soluble when reacting with an acidic aqueous solution.
(W)
alkane
In organic chemistry, an alkane, or paraffin (a historical name that also has other meanings) , is an acyclicsaturatedhydrocarbon. In other words, an alkane consists of hydrogen and carbon atoms arranged in a tree structure in which all the carbon–carbon bonds are single. Alkanes have the general chemical formula CnH2n+2. The alkanes range in complexity from the simplest case of methane (CH4), where n = 1 (sometimes called the parent molecule), to arbitrarily large and complex molecules, like pentacontane (C50H102) or 6-ethyl-2-methyl-5-(1-methylethyl) octane, an isomer of tetradecane (C14H30). (W)
Chemical structure of methane, the simplest alkane.
alternative splicingAlternative splicing, or alternative RNA splicing, or differential splicing, is a regulated process during gene expression that results in a single gene coding for multiple proteins. In this process, particular exons of a gene may be included within or excluded from the final, processed messenger RNA (mRNA) produced from that gene. Consequently, the proteins translated from alternatively spliced mRNAs will contain differences in their amino acid sequence and, often, in their biological functions (see Figure). Notably, alternative splicing allows the human genome to direct the synthesis of many more proteins than would be expected from its 20,000 protein-coding genes. (W)
Alternative splicing produces three protein isoforms.
Traditional classification of basic types of alternative RNA splicing events. Exons are represented as blue and yellow blocks, introns as lines in between.
Collection of basic alternative RNA splicing events.
Relative frequencies of types of alternative splicing events differ between humans and fruit flies.
Frequency of types of alternative splicing events Relative frequencies of types of alternative splicing events differ between vertebrates and invertebrates. Vertebrates generally have a preponderance of skipped or "cassette" exons; splicing events in invertebrates are more evenly distributed among the basic types. Data from Michael Sammeth; Sylvain Foissac; Roderic Guigó (8 August, 2008). "A general definition and nomenclature for alternative splicing events". PLoS Comput Biol. 4: e1000147. doi:10.1371/journal.pcbi.1000147. http://www.ploscompbiol.org/article/info:doi%2F10.1371%2Fjournal.pcbi.1000147.
Spliceosome A complex defines the 5' and 3' ends of the intron before removal.
Spliceosome assembly: the A complex. SR proteins bind to splicing enhancer sites, and assist with the binding of the U1 snRNP to the donor site and the U2AF proteins to the acceptor site and polypyrimidine tract. The U2 snRNP binds to the branch point.
Splicing repression.
Generalized model of splicing repression. Splicing repressor proteins (mostly hnRNPs) bind to splicing silencers in exons (ESS) and introns (ISS). They inhibit the binding of U1 snRNP to the donor site, and of U2AFs and the U2 snRNP to the acceptor site and branch point. This results in skipping of the exon (yellow). Information from: Black, Douglas L. (2003). "Mechanisms of alternative pre-messenger RNA splicing". Annual Reviews of Biochemistry 72 (1): 291-336. Wang, Z; Burge, Cb (May 2008). "Splicing regulation: from a parts list of regulatory elements to an integrated splicing code" (Free full text). RNA (New York, N.Y.) 14 (5): 802–13. doi:10.1261/rna.876308. ISSN 1355-8382. PMID 18369186. PMC: 2327353. .
Splicing activation.
Generalized model of splicing activation. Splicing activator proteins (mostly SR proteins) bind to splicing enhancers in exons (ESE) and introns (ISE). They assist in the binding of U1 snRNP to the donor site and of U2AFs and U2 snRNP to the acceptor site and branch point. Information from: Black, Douglas L. (2003). "Mechanisms of alternative pre-messenger RNA splicing". Annual Reviews of Biochemistry 72 (1): 291-336. Wang, Z; Burge, Cb (May 2008). "Splicing regulation: from a parts list of regulatory elements to an integrated splicing code" (Free full text). RNA (New York, N.Y.) 14 (5): 802–13. doi:10.1261/rna.876308. ISSN 1355-8382. PMID 18369186. PMC: 2327353.
Alternative splicing of dsx pre-mRNA.
Alternative splicing of Drosophila dsx gene. Pre-mRNAs from the D. melanogaster gene dsx contain 6 exons. In males, exons 1,2,3,5,and 6 are joined to form the mRNA, which encodes a transcriptional regulatory protein required for male development. In females, exons 1,2,3, and 4 are joined, and a polyadenylation signal in exon 4 causes cleavage of the mRNA at that point. The resulting mRNA is a transcriptional regulatory protein required for female development[1]. This is an example of exon skipping alternative splicing. The intron upstream from exon 4 has a weak-consensus polypyrimidine tract, to which U2AF proteins bind poorly without assistance from splicing activators. This 3' splice acceptor site is therefore not used in males. Females, however, produce the splicing activator Transformer (Tra). The SR protein Tra2 is produced in both sexes and binds to an ESE in exon 4; if Tra is present, it binds to Tra2 and, along with another SR protein, forms a complex that assists U2AF proteins in binding to the weak polypyrimidine tract. U2 is recruited to the associated branch point, and this leads to inclusion of exon 4 in the mRNA[1][2].Notes ↑ ab Lynch KW, Maniatis T (August 1996). "Assembly of specific SR protein complexes on distinct regulatory elements of the Drosophila doublesex splicing enhancer". Genes Dev.10 (16): 2089–101. PMID8769651.↑ Graveley BR, Hertel KJ, Maniatis T (June 2001). "The role of U2AF35 and U2AF65 in enhancer-dependent splicing". RNA7 (6): 806–18. PMID11421359.PMC:1370132. .
Alternative splicing of the DrosophilaTransformer gene product.
Alternative splicing of the Transformer gene transcript in Drosophila melanogaster. In males, the splicing factor U2AF binds to the 3' splice junction of intron 1, allowing the transcript to be spliced at this point. The mRNA then contains the entire exon 2, including an early stop codon. The protein encoded is truncated and non-functional. In females, the master sex determination factor Sex Lethal (Sxl) binds at the 3' splice junction, competing with U2AF. Splicing then occurs at an alternative 3' splice junction within exon 2. The mRNA that results encodes a functional Tra protein. .
Alternative splicing of the Fas receptor pre-mRNA.
Alternative splicing of HIV-1 tat exon 2.
Alternative splicing of HIV-1 tat exon 2. HIV-1 RNA is alternatively spliced in multiple ways. Equilibrium among differentially spliced transcripts, encoding different products, is required for viral multiplication. The inclusion of tat exon 2 in the RNA is regulated by competition between the splicing repressor hnRNP A1 and the SR protein SC35. Within exon 2 an ESS and ESE overlap. If A1 repressor binds, it initiates cooperative binding of multiple A1 molecules, extending into the 5’ donor site upstream of exon 2 and preventing the binding of U2AF35 to the polypyrimidine tract. If SC35 binds to the ESE, it prevents A1 binding and maintains the 5’ donor site in an accessible state for assembly of the spliceosome. Competition between the activator and repressor provides the required equilibrium among transcripts including and excluding exon 2.
Compounds with a nitrogen atom attached to a carbonyl group, thus having the structure R–CO–NR′R″, are called amides and have different chemical properties from amines. (W)
Primary (1°) amine.
Secondary (2°) amine.
Tertiary (3°) amine.
amino acidAmino acids are organic compounds that contain amine (-NH2) and carboxyl (-COOH) functional groups, along with a side chain (R group) specific to each amino acid. The key elements of an amino acid are carbon (C), hydrogen (H), oxygen (O), and nitrogen (N), although other elements are found in the side chains of certain amino acids. About 500 naturally occurring amino acids are known (though only 20 appear in the genetic code) and can be classified in many ways. (W)
amplicon
In molecular biology, an amplicon is a piece of DNA or RNA that is the source and/or product of amplification or replication events. It can be formed artificially, using various methods including polymerase chain reactions (PCR) or ligase chain reactions (LCR), or naturally through gene duplication. In this context, amplification refers to the production of one or more copies of a genetic fragment or target sequence, specifically the amplicon. As it refers to the product of an amplification reaction, amplicon is used interchangeably with common laboratory terms, such as "PCR product." (W)
An amplicon sequence template that has been prepared for amplification. The target sequence to be amplified is colored green.
Use of ATP to drive the endergonic process of anabolism.
Organisms are not at equilibrium. They require a continuous influx of free energy to maintain order. Organisms maintain their non-equilibrium status by coupling the exergonic reactions of nutrient oxidation to the endergonic processes required to maintain the living state (such as the performance of mechanical work, the active transport of molecules against concentration gradients, and the biosynthesis of complex molecules). ATP and NADH serve as energy carriers that link the breakdown of food and biosynthesis of cellular compounds.
Amino acid biosynthesis from intermediates of glycolysis and the citric acid cycle.
The drawn molecules are in their neutral forms and do not fully correspond to their presented names. Humans can not synthesize all of these amino acids.
annular lipid shellAnnular lipids (also called shell lipids or boundary lipids) are a set of lipids or lipidic molecules which preferentially bind or stick to the surface of membrane proteins in biological cells. They constitute a layer, or an annulus/ shell, of lipids which are partially immobilized due to the existence of lipid-protein interactions. Polar headgroups of these lipids bind to the hydrophilic part of the membrane protein(s) at the inner and outer surfaces of lipid bilayer membrane. The hydrophobic surface of the membrane proteins is bound to the apposed lipid fatty acid chains of the membrane bilayer. For integral membrane proteins spanning the thickness of the membrane bilayer, these annular/shell lipids may act like a lubricating layer on the proteins' surfaces, thereby facilitating almost free rotation and lateral diffusion of membrane proteins within the 2-dimensional expanse of the biological membrane(s). Outside the layer of shell/annular lipids, lipids are not tied down to protein molecules. However, they may be slightly restricted in their segmental motion freedom due to mild peer pressure of protein molecules, if present in high concentration, which arises from extended influence of protein-lipid interaction. Membrane areas away from protein molecules contain lamellar phase bulk lipids, which are largely free from any restraining effects due to protein-lipid interactions. Thermal denaturation of membrane proteins may destroy the secondary and tertiary structure of membrane proteins, exposing newer surfaces to membrane lipids and therefore increasing the number of lipids molecules in the annulus/shell layer. This phenomenon can be studied by the spin labelelectron paramagnetic resonance technique. (W)
anomer
An anomer is a type of geometric variation found at certain atoms in carbohydrate molecules. An epimer is a stereoisomer that differs in configuration at any single stereogenic center. An anomer is an epimer at the hemiacetal/hemiketal carbon in a cyclic saccharide, an atom called the anomeric carbon. The anomeric carbon is the carbon derived from the carbonyl carbon compound (the ketone or aldehyde functional group) of the open-chain form of the carbohydrate molecule. Anomerization is the process of conversion of one anomer to the other. As is typical for stereoisomeric compounds, different anomers have different physical properties, melting points and specific rotations.
The word "anomer" is derived from the Greek word ἄνω, meaning "up, above", and the Greek word μέρος (“part”), as in "isomer". (W)
anti small RNA
Antisense small RNA are short RNA sequences (about 50-500 nucleotides long) that are complementary to other small RNA (sRNA) in the cell.
sRNAs can repress translation via complementary base-pairing with their target mRNA sequence. Anti-sRNAs function by complementary pairing with sRNAs before the mRNA can be bound, thus freeing the mRNA and relieving translation inhibition. (W)
Proposed mechanism for anti-sRNA relief of sRNA mediated translation inhibition.
Consensus secondary structure of Anti GcvB sRNA.
Consensus secondary structure of Anti stx2 sRNA.
antibody
An antibody (Ab), also known as an immunoglobulin (Ig), is a large, Y-shaped protein produced mainly by plasma cells that is used by the immune system to neutralize pathogens such as pathogenic bacteria and viruses. The antibody recognizes a unique molecule of the pathogen, called an antigen, via the fragment antigen-binding (Fab) variable region. Each tip of the "Y" of an antibody contains a paratope (analogous to a lock) that is specific for one particular epitope (analogous to a key) on an antigen, allowing these two structures to bind together with precision. Using this binding mechanism, an antibody can tag a microbe or an infected cell for attack by other parts of the immune system, or can neutralize its target directly (for example, by inhibiting a part of a microbe that is essential for its invasion and survival). Depending on the antigen, the binding may impede the biological process causing the disease or may activate macrophages to destroy the foreign substance. The ability of an antibody to communicate with the other components of the immune system is mediated via its Fc region (located at the base of the "Y"), which contains a conserved glycosylation site involved in these interactions. The production of antibodies is the main function of the humoral immune system.
Antibodies are secreted by B cells of the adaptive immune system, mostly by differentiated B cells called plasma cells. Antibodies can occur in two physical forms, a soluble form that is secreted from the cell to be free in the blood plasma, and a membrane-bound form that is attached to the surface of a B cell and is referred to as the B-cell receptor (BCR). The BCR is found only on the surface of B cells and facilitates the activation of these cells and their subsequent differentiation into either antibody factories called plasma cells or memory B cells that will survive in the body and remember that same antigen so the B cells can respond faster upon future exposure. In most cases, interaction of the B cell with a T helper cell is necessary to produce full activation of the B cell and, therefore, antibody generation following antigen binding. Soluble antibodies are released into the blood and tissue fluids, as well as many secretions to continue to survey for invading microorganisms. (W)
Each antibody binds to a specific antigen; an interaction similar to a lock and key.
Several immunoglobulin domains make up the two heavy chains (red and blue) and the two light chains (green and yellow) of an antibody. The immunoglobulin domains are composed of between 7 (for constant domains) and 9 (for variable domains) β-strands..
antibody (Ab) = immunoglobulin (Ig)
An antibody (Ab), also known as an immunoglobulin (Ig), is a large, Y-shaped protein produced mainly by plasma cells that is used by the immune system to neutralize pathogens such as pathogenic bacteria and viruses. The antibody recognizes a unique molecule of the pathogen, called an antigen, via the fragment antigen-binding (Fab) variable region. Each tip of the "Y" of an antibody contains a paratope (analogous to a lock) that is specific for one particular epitope (analogous to a key) on an antigen, allowing these two structures to bind together with precision. Using this binding mechanism, an antibody can tag a microbe or an infected cell for attack by other parts of the immune system, or can neutralize its target directly (for example, by inhibiting a part of a microbe that is essential for its invasion and survival). Depending on the antigen, the binding may impede the biological process causing the disease or may activate macrophages to destroy the foreign substance. The ability of an antibody to communicate with the other components of the immune system is mediated via its Fc region (located at the base of the "Y"), which contains a conserved glycosylation site involved in these interactions. The production of antibodies is the main function of the humoral immune system.
Antibodies are secreted by B cells of the adaptive immune system, mostly by differentiated B cells called plasma cells. Antibodies can occur in two physical forms, a soluble form that is secreted from the cell to be free in the blood plasma, and a membrane-bound form that is attached to the surface of a B cell and is referred to as the B-cell receptor (BCR). The BCR is found only on the surface of B cells and facilitates the activation of these cells and their subsequent differentiation into either antibody factories called plasma cells or memory B cells that will survive in the body and remember that same antigen so the B cells can respond faster upon future exposure. In most cases, interaction of the B cell with a T helper cell is necessary to produce full activation of the B cell and, therefore, antibody generation following antigen binding. Soluble antibodies are released into the blood and tissue fluids, as well as many secretions to continue to survey for invading microorganisms. (W)
Each antibody binds to a specific antigen; an interaction similar to a lock and key.
Schematic diagram of an antibody and antigens. Color scheme loosely made to match Image:Antibody scheme.svg. Light chains are in lighter blue and orange, heavy chains in darker blue and orange.
1) Antibodies (A) and pathogens (B) free roam in the blood. 2) The antibodies bind to pathogens, and can do so in different formations such as: opsonization (2a), neutralisation (2b), and agglutination (2c). 3) A phagocyte (C) approaches the pathogen, and the Fc region (D) of the antibody binds to one of the Fc receptors (E) of the phagocyte. 4) Phagocytosis occurs as the pathogen is ingested.
In immunology, an antigen (Ag) is a molecule or molecular structure, such as may be present at the outside of a pathogen, that can be bound by an antigen-specific antibody or B cell antigen receptor. The presence of antigens in the body normally triggers an immune response. The Ag abbreviation stands for an antibody generator.
Antigens are "targeted" by antibodies. Each antibody is specifically produced by the immune system to match an antigen after cells in the immune system come into contact with it; this allows a precise identification or matching of the antigen and the initiation of an adaptive response. The antibody is said to "match" the antigen in the sense that it can bind to it due to an adaptation in a antigen-binding fragment of the antibody. In most cases, an adapted antibody can only react to and bind one specific antigen; in some instances, however, antibodies may cross-react and bind more than one antigen.
Antigens are proteins, peptides (amino acid chains) and polysaccharides (chains of monosaccharides/simple sugars) but lipids and nucleic acids become antigens only when combined with proteins and polysaccharides.
The antigen may originate from within the body ("self-antigen") or from the external environment ("non-self"). The immune system identifies and attacks "non-self" external antigens and usually does not react to self-antigens due to negative selection of T cells in the thymus.
Vaccines are examples of antigens in an immunogenic form, which are intentionally administered to a recipient to induce the memory function of adaptive immune system toward the antigens of the pathogen invading that recipient, with the seasonal flu virus as a common example. (W)
Antigen processing, or the cytosolic pathway, is an immunological process that prepares antigens for presentation to special cells of the immune system called T lymphocytes. It is considered to be a stage of antigen presentation pathways. This process involves two distinct pathways for processing of antigens from an organism's own (self) proteins or intracellularpathogens (e.g. viruses), or from phagocytosed pathogens (e.g. bacteria); subsequent presentation of these antigens on class I or class IImajor histocompatibility complex (MHC) molecules is dependent on which pathway is used. Both MHC class I and II are required to bind antigen before they are stably expressed on a cell surface. MHC I antigen presentation typically (considering cross-presentation) involves the endogenous pathway of antigen processing, and MHC II antigen presentation involves the exogenous pathway of antigen processing. Cross-presentation involves parts of the exogenous and the endogenous pathways but ultimately involves the latter portion of the endogenous pathway (e.g. proteolysis of antigens for binding to MHC I molecules).
While the joint distinction between the two pathways is useful, there are instances where extracellular-derived peptides are presented in the context of MHC class I and cytosolic peptides are presented in the context of MHC class II (this often happens in dendritic cells). (W)
antigenic driftAntigenic drift is a kind of genetic variation in viruses, arising by the accumulation of mutations in the virus genes that code for virus-surface proteins that host antibodies recognize. This results in a new strain of virus particles that is not effectively inhibited by the antibodies that prevented infection by previous strains. This makes it easier for the changed virus to spread throughout a partially immune population. Antigenic drift occurs in both influenza A and influenza B viruses. (W)
antigenic shift
Antigenic shift is the process by which two or more different strains of a virus, or strains of two or more different viruses, combine to form a new subtype having a mixture of the surface antigens of the two or more original strains. The term is often applied specifically to influenza, as that is the best-known example, but the process is also known to occur with other viruses, such as visna virus in sheep. Antigenic shift is a specific case of reassortment or viral shift that confers a phenotypic change.
Antigenic shift is contrasted with antigenic drift, which is the natural mutation over time of known strains of influenza (or other things, in a more general sense) which may lead to a loss of immunity, or in vaccine mismatch. Antigenic drift occurs in all types of influenza including influenza A,influenza B and influenza C. Antigenic shift, however, occurs only in influenza A because it infects more than just humans. Affected species include other mammals and birds, giving influenza A the opportunity for a major reorganization of surface antigens. Influenza B and C principally infect humans, minimizing the chance that a reassortment will change its phenotype drastically.(W)
NIAID illustration of potential influenza genetic reassortment.
The different types of topologies in G-quadruplex, propeller, lateral, and diagonal.
(A) A putative quadruplex sequence (PQS) is a nucleotide sequence predicted to form a G4 structure. A degenerate PQS used to predict the formation of intramolecular G4s is shown here, consisting of four runs of at least three guanines per run, separated by short stretches of other bases (N). (B) The basic unit of the G4 is the G-tetrad. (C) G4 structures display a large variety of different topologies. Topology of intramolecular G4 structures displaying antiparallel (left) and parallel (right) configurations. (D) Topology of intermolecular G4 structures formed by dimerisation of four strands (left) or two strands (right). Harris LM, Merrick CJ (2015) G-Quadruplexes in Pathogens: A Common Route to Virulence Control? PLoS Pathog 11(2): e1004562. doi:10.1371/journal.ppat.1004562 (W)
TAntiparallel and parallel beta sheet.
antisense RNAAntisense RNA (asRNA), also referred to as antisense transcript, natural antisense transcript (NAT) or antisense oligonucleotide, is a single stranded RNA that is complementary to a protein coding messenger RNA (mRNA) with which it hybridizes, and thereby blocks its translation into protein. asRNAs (which occur naturally) have been found in both prokaryotes and eukaryotes, antisense transcripts can be classified into short (<200 nucleotides) and long (>200 nucleotides) non-coding RNAs (ncRNAs). The primary function of asRNA is regulating gene expression. asRNAs may also be produced synthetically and have found wide spread use as research tools for gene knockdown. They may also have therapeutic applications.(W)
AsRNA is transcribed from the lagging strand of a gene and is complementary to a specific mRNA or sense transcript.
'Epigenetic regulation:' a) AsRNAs can induce DNA methylation by recruiting a DNA methyltransferase (DNMT). b) AsRNAs can induce histone methylation by recruiting of a histone methyltransferase (HMT). 'Co-transcriptional regulation:' c) AsRNAs can cause RNA polymerase (Pol) collision and stop the transcription. d) AsRNAs can preference translation of a specific splice variant (mRNA V1) by blocking the other splice variant (mRNA V2). 'Post-transcriptional regulation:' e) AsRNA-mRNA duplex can either block ribosome from binding to the mRNA or recruit RNase H to degrade the mRNA. By this mechanism, asRNAs directly inhibit translation of the mRNAs.
AP endonuclease
Apurinic/apyrimidinic (AP) endonuclease is an enzyme that is involved in the DNAbase excision repair pathway (BER). Its main role in the repair of damaged or mismatched nucleotides in DNA is to create a nick in the phosphodiester backbone of the AP site created when DNA glycosylase removes the damaged base.
There are four types of AP endonucleases that have been classified according to their mechanism and site of incision. Class I AP endonucleases (EC4.2.99.18) cleave 3′ to AP sites by a β-lyase mechanism, leaving an unsaturated aldehyde, termed a 3′-(4-hydroxy-5-phospho-2-pentenal) residue, and a 5′-phosphate. Class II AP endonucleases incise DNA 5′ to AP sites by a hydrolytic mechanism, leaving a 3′-hydroxyl and a 5′-deoxyribose phosphate residue.[2] Class III and class IV AP endonucleases also cleave DNA at the phosphate groups 3′ and 5′ to the baseless site, but they generate a 3′-phosphate and a 5′-OH. (W)
Ribbon diagram of APE1. PDB = 1de9.
Hydrogen bonding among key amino acid residues help stabilize active site structure. Moreover, a negatively charged residue (Glu 96) helps hold the Mg2+ also needed to stabilize the AP site in place PDB 1de9.
Positive residues on the surface of the APE1 protein (in blue) anchor and bend DNA though interactions with DNA's negative phosphate groups. PDB 1de9.
Positive amino acid residues on the surface of AP endonuclease kink DNA in order to induce the fit of the AP site in the active site.
AP site
In biochemistry and molecular genetics, an AP site (apurinic/apyrimidinic site), also known as an abasic site, is a location in DNA (also in RNA but much less likely) that has neither a purine nor a pyrimidine base, either spontaneously or due to DNA damage. It has been estimated that under physiological conditions 10,000 apurinic sites and 500 apyrimidinic may be generated in a cell daily.
AP sites can be formed by spontaneous depurination, but also occur as intermediates in base excision repair. In this process, a DNA glycosylase recognizes a damaged base and cleaves the N-glycosidic bond to release the base, leaving an AP site. A variety of glycosylases that recognize different types of damage exist, including oxidized or methylated bases, or uracil in DNA. The AP site can then be cleaved by an AP endonuclease, leaving 3' hydroxyl and 5' deoxyribosephosphate termini (see DNA structure). In alternative fashion, bifunctional glycosylase-lyases can cleave the AP site, leaving a 5' phosphate adjacent to a 3' α,β-unsaturated aldehyde. Both mechanisms form a single-strand break, which is then repaired by either short-patch or long-patch base excision repair.
If left unrepaired, AP sites can lead to mutation during semiconservative replication. They can cause replication fork stalling and are bypassed by translesion synthesis. In E. coli, adenine is preferentially inserted across from AP sites, known as the "A rule". The situation is more complex in higher eukaryotes, with different nucleotides showing a preference depending on the organism and experimental conditions. (W)
Simple representation of an AP Site.
AP site reactivity.
aqueous solution
An aqueous solution is a solution in which the solvent is water. It is mostly shown in chemical equations by appending (aq) to the relevant chemical formula. For example, a solution of table salt, or sodium chloride (NaCl), in water would be represented as Na+(aq) + Cl-(aq). The word aqueous (which comes from aqua) means pertaining to, related to, similar to, or dissolved in, water. As water is an excellent solvent and is also naturally abundant, it is a ubiquitous solvent in chemistry. Aqueous solution is water with a pH of 7.0 where the hydrogen ions (H+) and hydroxide ions (OH-) are in Arrhenius balance (10-7).
The first solvation shell of a sodium ion dissolved in water.
Argonaute
The Argonauteprotein family plays a central role in RNA silencing processes, as essential components of the RNA-induced silencing complex (RISC). RISC is responsible for the gene silencing phenomenon known as RNA interference (RNAi). Argonaute proteins bind different classes of small non-coding RNAs, including microRNAs (miRNAs), small interfering RNAs (siRNAs) and Piwi-interacting RNAs (piRNAs). Small RNAs guide Argonaute proteins to their specific targets through sequence complementarity (base pairing), which then leads to mRNA cleavage or translation inhibition.
The name of this protein family is derived from a mutant phenotype resulting from mutation of AGO1 in Arabidopsis thaliana, which was likened by Bohmert et al. to the appearance of the pelagic octopus Argonauta argo. (W)
An argonaute protein from Pyrococcus furiosus; these proteins are the catalytic endonucleases in the RNA-induced silencing complex, the protein complex that mediates the RNA interference phenomenon.
Left: A full-length argonaute protein from the archaea species Pyrococcus furiosus.PDB1U04. Right: The PIWI domain of an argonaute protein in complex with double-stranded RNAPDB1YTU. The base-stacking interaction between the 5′ base on the guide strand and a conserved tyrosine residue (light blue) is highlighted; the stabilizing divalent cation (magnesium) is shown as a gray sphere.
Lentiviral delivery of designed shRNA's and the mechanism of RNA interference in mammalian cells.
atomic number
The atomic number or proton number (symbol Z) of a chemical element is the number of protons found in the nucleus of every atom of that element. The atomic number uniquely identifies a chemical element. It is identical to the charge number of the nucleus. In an uncharged atom, the atomic number is also equal to the number of electrons.(W)
atomic orbital
In atomic theory and quantum mechanics, an atomic orbital is a mathematical function that describes the wave-like behavior of either one electron or a pair of electrons in an atom. This function can be used to calculate the probability of finding any electron of an atom in any specific region around the atom's nucleus. The term atomic orbital may also refer to the physical region or space where the electron can be calculated to be present, as predicted by the particular mathematical form of the orbital.
Atomic orbitals are the basic building blocks of the atomic orbital model (alternatively known as the electron cloud or wave mechanics model), a modern framework for visualizing the submicroscopic behavior of electrons in matter. In this model the electron cloud of a multi-electron atom may be seen as being built up (in approximation) in an electron configuration that is a product of simpler hydrogen-like atomic orbitals. The repeating periodicity of the blocks of 2, 6, 10, and 14 elements within sections of the periodic table arises naturally from the total number of electrons that occupy a complete set of s, p, d, and f atomic orbitals, respectively, although for higher values of the quantum number n, particularly when the atom in question bears a positive charge, the energies of certain sub-shells become very similar and so the order in which they are said to be populated by electrons (e.g. Cr = [Ar]4s13d5 and Cr2+ = [Ar]3d4) can only be rationalized somewhat arbitrarily. (W)
The shapes of the first five atomic orbitals are: 1s, 2s, 2px, 2py, and 2pz. The two colors show the phase or sign of the wave function in each region. Each picture is domain coloring of a ψ(x, y, z) function which depend on the coordinates of one electron. To see the elongated shape of ψ(x, y, z)2 functions that show probability density more directly, see pictures of d-orbitals below.
Atomic orbitals of the electron in a hydrogen atom at different energy levels. The probability of finding the electron is given by the color, as shown in the key at upper right..
ATPase
ATPases (EC3.6.1.3, adenylpyrophosphatase, ATP monophosphatase, triphosphatase, SV40 T-antigen, adenosine 5'-triphosphatase, ATP hydrolase, complex V (mitochondrial electron transport), (Ca2+ + Mg2+)-ATPase, HCO3--ATPase, adenosine triphosphatase) are a class of enzymes that catalyze the decomposition of ATP into ADP and a free phosphate ion or the inverse reaction. This dephosphorylation reaction releases energy, which the enzyme (in most cases) harnesses to drive other chemical reactions that would not otherwise occur. This process is widely used in all known forms of life.
Example of primary active transport, where energy from hydrolysis of ATP is directly coupled to the movement of a specific substance across a membrane independent of any other species.
autocrine signalingAutocrine signaling is a form of cell signaling in which a cell secretes a hormone or chemical messenger (called the autocrine agent) that binds to autocrine receptors on that same cell, leading to changes in the cell. This can be contrasted with paracrine signaling, intracrine signaling, or classical endocrine signaling. (W)
autophosphorylationAutophosphorylation is a type of post-translational modification of proteins. It is generally defined as the phosphorylation of the kinase by itself. In eukaryotes, this process occurs by the addition of a phosphate group to serine,threonine or tyrosine residues within protein kinases, normally to regulate the catalytic activity. Autophosphorylation may occur when a kinases' own active site catalyzes the phosphorylation reaction (cis autophosphorylation), or when another kinase of the same type provides the active site that carries out the chemistry (trans autophosphorylation). The latter often occurs when kinase molecules dimerize. In general, the phosphate groups introduced are gamma phosphates from nucleoside triphosphates, most commonly ATP.(W)
Fig. 1: Activation of the Epidermal Growth Factor Receptor by autophosphorylation. Adapted from Pecorino (2008).
Fig. 2: Regulation of Src-kinase by autophosphorylation. Adapted from Frame (2002).
autosome
An autosome is any chromosome that is not a sex chromosome (an allosome). The members of an autosome pair in a diploid cell have the same morphology, unlike those in allosome pairs which may have different structures. The DNA in autosomes is collectively known as atDNA or auDNA.
For example, humans have a diploidgenome that usually contains 22 pairs of autosomes and one allosome pair (46 chromosomes total). The autosome pairs are labeled with numbers (1–22 in humans) roughly in order of their sizes in base pairs, while allosomes are labelled with their letters. By contrast, the allosome pair consists of two X chromosomes in females or one X and one Y chromosome in males. Unusual combinations of XYY,XXY,XXX,XXXX,XXXXX or XXYY, among other allosome combinations, are known to occur and usually cause developmental abnormalities.
Autosomes still contain sexual determination genes even though they are not sex chromosomes. For example, the SRY gene on the Y chromosome encodes the transcription factor TDF and is vital for male sex determination during development. TDF functions by activating the SOX9 gene on chromosome 17, so mutations of the SOX9 gene can cause humans with an ordinary Y chromosome to develop as females. (W)
Human metaphase chromosomes were subjected to fluorescence in situ hybridization with a probe to the Alu Sequence (green signals)and counterstained for DNA (red).
There are two copies of each autosome (chromosomes 1–22) in both females and males. The sex chromosomes are different: There are two copies of the X-chromosome in females, but males have a single X-chromosome and a Y-chromosome.
The numeric value of the Avogadro constant expressed in reciprocal mole, a dimensionless number, is called the Avogadro number, sometimes denoted N or N0, which is thus the number of particles that are contained in one mole, exactly 6.02214076×1023.
The value of the Avogadro constant was chosen so that the mass of one mole of a chemical compound, in grams, is numerically equal (for all practical purposes) to the average mass of one molecule of the compound, in daltons (universal atomic mass units);one dalton being 1/12 of the mass of one carbon-12 atom, which is approximately the mass of one nucleon (proton or neutron). Twelve grams of carbon contains one mole of carbon atoms.
For example, the average mass of one molecule of water is about 18.0153 daltons, and one mole of water (N molecules) is about 18.0153 grams.(W)
b
B-cell receptor
The B cell receptor (BCR) is a transmembrane protein on the surface of a B cell. B cell receptors are composed of immunoglobulinmolecules that form a type 1 transmembranereceptor protein, and are typically located on the outer surface of these lymphocyte cells. Through biochemical signaling and by physically acquiring antigens from the immune synapses, the BCR controls the activation of the B cell. B cells are able to gather and grab antigens by engaging biochemical modules for receptor clustering, cell spreading, generation of pulling forces, and receptor transport, which eventually culminates in endocytosis and antigen presentation. B cells’ mechanical activity adheres to a pattern of negative and positive feedbacks that regulate the quantity of removed antigen by manipulating the dynamic of BCR-antigen bonds directly. Particularly, grouping and spreading increase the relation of antigen with BCR, thereby proving sensitivity and amplification. On the other hand, pulling forces delinks the antigen from the BCR, thus testing the quality of antigen binding.(W)
The B cell receptor (BCR) is a transmembrane protein on the surface of a B cell. A B cell receptor includes both CD79 and the immunoglobulin. The plasma membrane of a B cell is indicated by the green phospholipids. The B cell receptor extends both outside the cell (above the plasma membrane) and inside the cell (below the membrane).
The general structure of the B-cell receptor includes a membrane-boundimmunoglobulin molecule and a signal transduction region. Disulfide bridges connect the immunoglobulin isotype and the signal transduction region.
.
Schematic representation of the B cell receptor signaling pathways. Aggregation of the BCR quickly activate Src family kinases, including Blk, LYN, and FYN and the SYK and BTKtyrosine kinases. As such, the process catalyzes the formation of a ‘signalosome’ that consists of the aforementioned tyrosine kinases, the BCR and the adaptor proteins, for instance, BLNK and CD19, as well as signaling molecules, such as P13K, PLCy2, and VAV.
backbone chain
In polymer science, the backbone chain of a polymer is the longest series of covalently bonded atoms that together create the continuous chain of the molecule. This science is subdivided into the study of organic polymers, which consist of a carbon backbone, and inorganic polymers which have backbones containing only main group elements.
In biochemistry,organic backbone chains make up the primary structure of macromolecules. The backbones of these biological macromolecules consist of central chains of covalently bonded atoms. The characteristics and order of the monomer residues in the backbone make a map for the complex structure of biological polymers (see Biomolecular structure). The backbone is, therefore, directly related to biological molecules’ function. The macromolecules within the body can be divided into four main subcategories, each of which are involved in very different and important biological processes: proteins, carbohydrates,lipids, and nucleic acids. Each of these molecules has a different backbone and consists of different monomers each with distinctive residues and functionalities. This is the driving factor of their different structures and functions in the body. Although lipids have a "backbone," they are not true biological polymers as their backbone is a three carbon molecule, glycerol, with longer substituent "side chains." For this reason, only proteins, carbohydrates, and nucleic acids should be considered as biological macromolecules with polymeric backbones.(W)
Bacterial conjugation is the transfer of genetic material between bacterial cells by direct cell-to-cell contact or by a bridge-like connection between two cells. This takes place through a pilus. It is a parasexual mode of reproduction in bacteria.
Schematic drawing of bacterial conjugation. Conjugation diagram 1- Donor cell produces pilus. 2- Pilus attaches to recipient cell, brings the two cells together. 3- The mobile plasmid is nicked and a single strand of DNA is then transferred to the recipient cell. 4- Both cells recircularize their plasmids, synthesize second strands, and reproduce pili; both cells are now viable donors.
1.The insertion sequences (yellow) on both the F factor plasmid and the chromosome have similar sequences, allowing the F factor to insert itself into the genome of the cell. This is called homologous recombination and creates an Hfr (high frequency of recombination) cell. 2.The Hfr cell forms a pilus and attaches to a recipient F- cell. 3.A nick in one strand of the Hfr cell's chromosome is created. 4.DNA begins to be transferred from the Hfr cell to the recipient cell while the second strand of its chromosome is being replicated. 5.The pilus detaches from the recipient cell and retracts. The Hfr cell ideally wants to transfer its entire genome to the recipient cell. However, due to its large size and inability to keep in contact with the recipient cell, it is not able to do so. 6.a. The F- cell remains F- because the entire F factor sequence was not received. Since no homologous recombination occurred, the DNA that was transferred is degraded by enzymes. b. In very rare cases, the F factor will be completely transferred and the F- cell will become an Hfr cell.
Concentrated or strong bases are caustic on organic matter and react violently with acidic substances.
Aqueous solutions or molten bases dissociate in ions and conduct electricity.
Reactions with indicators: bases turn red litmus paper blue, phenolphthalein pink, keep bromothymol blue in its natural colour of blue, and turn methyl orange-yellow.
The pH of a basic solution at standard conditions is greater than seven.
base excision repairBase excision repair (BER) is a cellular mechanism, studied in the fields of biochemistry and genetics, that repairs damaged DNA throughout the cell cycle. It is responsible primarily for removing small, non-helix-distorting base lesions from the genome. The related nucleotide excision repair pathway repairs bulky helix-distorting lesions. BER is important for removing damaged bases that could otherwise cause mutations by mispairing or lead to breaks in DNA during replication. BER is initiated by DNA glycosylases, which recognize and remove specific damaged or inappropriate bases, forming AP sites. These are then cleaved by an AP endonuclease. The resulting single-strand break can then be processed by either short-patch (where a single nucleotide is replaced) or long-patch BER (where 2–10 new nucleotides are synthesized). (W)
Basic steps of base excision repair.
Uracil DNA glycosylase flips a uracil residue out of the duplex, shown in yellow.
Human uracil-DNA glycosylase bound to its DNA substrate. The uracil is coloured in yellow. Created from PDB 4SKN Reference "A nucleotide-flipping mechanism from the structure of human uracil-DNA glycosylase bound to DNA." Slupphaug G, Mol CD, Kavli B, Arvai AS, Krokan HE, Tainer JA. Nature. 1996 Nov 7;384(6604):87-92. PMID 8900285.
Demethylation of 5-Methylcytosine (5mC) in DNA. As reviewed in 2018, 5mC is oxidized by the ten-eleven translocation (TET) family of dioxygenases (TET1,TET2,TET3) to generate 5-hydroxymethylcytosine (5hmC). In successive steps TET enzymes further hydroxylate 5hmC to generate 5-formylcytosine (5fC) and 5-carboxylcytosine (5caC). Thymine-DNA glycosylase (TDG) recognizes the intermediate bases 5fC and 5caC and excises the glycosidic bond resulting in an apyrimidinic site (AP site). In an alternative oxidative deamination pathway, 5hmC can be oxidatively deaminated by activity-induced cytidine deaminase/apolipoprotein B mRNA editing complex (AID/APOBEC) deaminases to form 5-hydroxymethyluracil (5hmU) or 5mC can be converted to thymine (Thy). 5hmU can be cleaved by TDG, single-strand-selective monofunctional uracil-DNA glycosylase 1 (SMUG1), Nei-Like DNA Glycosylase 1 (NEIL1), or methyl-CpG binding protein 4 (MBD4). AP sites and T:G mismatches are then repaired by base excision repair (BER) enzymes to yield cytosine (Cyt).
base, organic
An organic base is an organic compound which acts as a base. Organic bases are usually, but not always, proton acceptors. They usually contain nitrogen atoms, which can easily be protonated. For example, amines or nitrogen-containing heterocyclic compounds have a lone pair of electrons on the nitrogen atom and can thus act as proton acceptors. Examples include:
A base pair (bp) is a fundamental unit of double-stranded nucleic acids consisting of two nucleobases bound to each other by hydrogen bonds. They form the building blocks of the DNA double helix and contribute to the folded structure of both DNA and RNA. Dictated by specific hydrogen bonding patterns, "Watson–Crick" base pairs (guanine–cytosine and adenine–thymine) allow the DNA helix to maintain a regular helical structure that is subtly dependent on its nucleotide sequence. The complementary nature of this based-paired structure provides a redundant copy of the genetic information encoded within each strand of DNA. The regular structure and data redundancy provided by the DNA double helix make DNA well suited to the storage of genetic information, while base-pairing between DNA and incoming nucleotides provides the mechanism through which DNA polymerase replicates DNA and RNA polymerase transcribes DNA into RNA. Many DNA-binding proteins can recognize specific base-pairing patterns that identify particular regulatory regions of genes.
Intramolecular base pairs can occur within single-stranded nucleic acids. This is particularly important in RNA molecules (e.g., transfer RNA), where Watson–Crick base pairs (guanine–cytosine and adenine–uracil) permit the formation of short double-stranded helices, and a wide variety of non-Watson–Crick interactions (e.g., G–U or A–A) allow RNAs to fold into a vast range of specific three-dimensional structures. In addition, base-pairing between transfer RNA (tRNA) and messenger RNA (mRNA) forms the basis for the molecular recognition events that result in the nucleotide sequence of mRNA becoming translated into the amino acid sequence of proteins via the genetic code.
The size of an individual gene or an organism's entire genome is often measured in base pairs because DNA is usually double-stranded. Hence, the number of total base pairs is equal to the number of nucleotides in one of the strands (with the exception of non-coding single-stranded regions of telomeres). The haploidhuman genome (23 chromosomes) is estimated to be about 3.2 billion bases long and to contain 20,000–25,000 distinct protein-coding genes. A kilobase (kb) is a unit of measurement in molecular biology equal to 1000 base pairs of DNA or RNA. The total number of DNA base pairs on Earth is estimated at 5.0×1037 with a weight of 50 billion tonnes. In comparison, the total mass of the biosphere has been estimated to be as much as 4 TtC (trillion tons of carbon).(W)
Depiction of the adenine–thymine Watson–Crick base pair.
bHLH transcription factors are often important in development or cell activity. For one, BMAL1-Clock is a core transcription complex in the molecular circadian clock. Other genes, like c-Myc and HIF-1, have been linked to cancer due to their effects on cell growth and metabolism. (W)
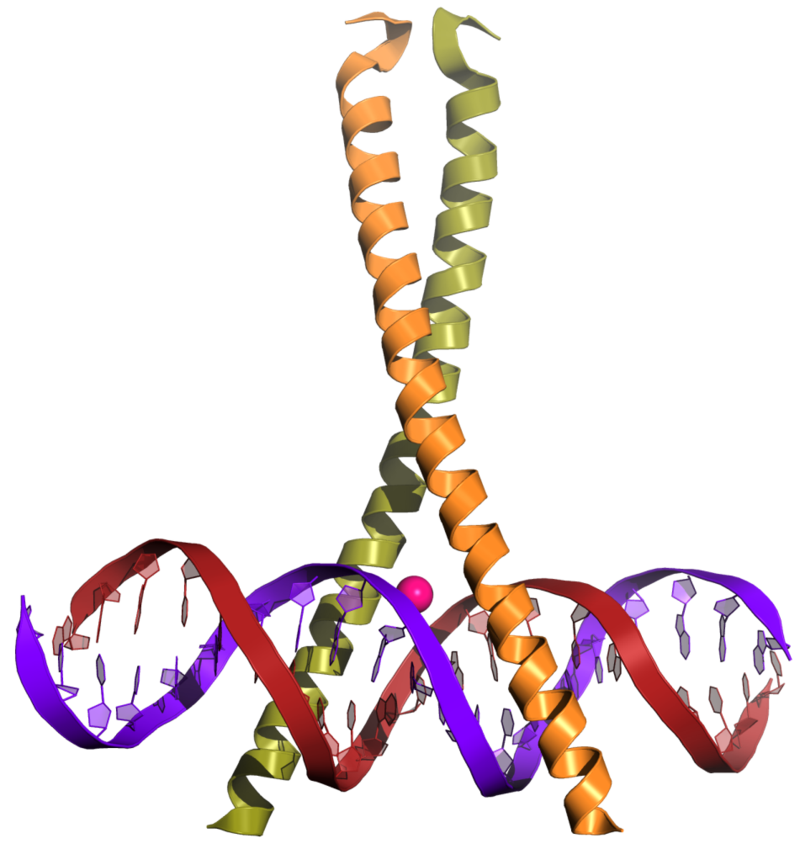
Basic helix-loop-helix DNA-binding domain
Basic helix-loop-helix structural motif of ARNT. Two α-helices (blue) are connected by a short loop (red).
Basic-helix-loop-helix structural motif of proteins. Two helices (blue) are connected by a short loop region (red). Based on the structure of Aryl hydrocarbon receptor nuclear translocator (ARNT): PDB ID 1X0o.
beta barrel
A beta barrel is a beta-sheet composed of tandem repeats that twists and coils to form a closed toroidal structure in which the first strand is bonded to the last strand (hydrogen bond). Beta-strands in many beta-barrels are arranged in an antiparallel fashion. Beta barrel structures are named for resemblance to the barrels used to contain liquids. Most of them are water-soluble proteins and frequently bind hydrophobicligands in the barrel center, as in lipocalins. Others span cell membranes and commonly found in porins. Porin-like barrel structures are encoded by as many as 2–3% of the genes in Gram-negative bacteria. (W)
Side view of a single monomer of a sucrose porin protein from the bacterium Salmonella typhimurium, illustrating the canonical antiparallel beta barrel structure. Porins are transmembrane proteins that facilitate transfer of small molecules such as sucrose that are polar or charged and therefore cannot diffuse through the hydrophobic cell membrane.. (W)
8-strand β barrel. Human retinol-binding protein bound to retinol (vitamin A) in blue. (PDB:1RBP).
Human retinol-binding protein (RBP) in complex with retinol, illustrating the canonical eight-stranded beta-barrel lipocalin structure.
Front view
Right view (90° rotation)
Back view (180° rotation)
Left view (270° rotation)
1 of 4 slabs showing the hydrogen bonding and residue names in the strands of the beta barrel of protein 1RRX.pdb, "green fluorescent protein".
Second of 4 slabs showing the hydrogen bonding and residue names in the strands of the beta barrel of protein 1RRX.pdb, "green fluorescent protein".
Third of 4 slabs showing the hydrogen bonding and residue names in the strands of the beta barrel of protein 1RRX.pdb, "green fluorescent protein".
Fourth of 4 slabs showing the hydrogen bonding and residue names in the strands of the beta barrel of protein 1RRX.pdb, "green fluorescent protein".
Table for calculating the shear number. The strand order in this barrel (GFP) is: 1 6 5 4 9 8 7 10 11 3 2.
A biochemical cascade, also known as a signaling cascade or signaling pathway, is a series of chemical reactions that occur within a biological cell when initiated by a stimulus. This stimulus, known as a first messenger, acts on a receptor that is transduced to the cell interior through second messengers which amplify the signal and transfer it to effector molecules, causing the cell to respond to the initial stimulus. Most biochemical cascades are series of events, in which one event triggers the next, in a linear fashion. At each step of the signaling cascade, various controlling factors are involved to regulate cellular actions, in order to respond effectively to cues about their changing internal and external environments.
An example would be the coagulation cascade of secondary hemostasis which leads to fibrin formation, and thus, the initiation of blood coagulation. Another example, sonichedgehog signaling pathway, is one of the key regulators of embryonic development and is present in all bilaterians. Signaling proteins give cells information to make the embryo develop properly. When the pathway malfunctions, it can result in diseases like basal cell carcinoma. Recent studies point to the role of hedgehog signaling in regulating adult stem cells involved in maintenance and regeneration of adult tissues. The pathway has also been implicated in the development of some cancers. Drugs that specifically target hedgehog signaling to fight diseases are being actively developed by a number of pharmaceutical companies. (W)
biomolecular structure
Biomolecular structure is the intricate folded, three-dimensional shape that is formed by a molecule of protein,DNA, or RNA, and that is important to its function. The structure of these molecules may be considered at any of several length scales ranging from the level of individual atoms to the relationships among entire protein subunits. This useful distinction among scales is often expressed as a decomposition of molecular structure into four levels: primary, secondary, tertiary, and quaternary. The scaffold for this multiscale organization of the molecule arises at the secondary level, where the fundamental structural elements are the molecule's various hydrogen bonds. This leads to several recognizable domains of protein structure and nucleic acid structure, including such secondary-structure features as alpha helixes and beta sheets for proteins, and hairpin loops, bulges, and internal loops for nucleic acids. The terms primary, secondary, tertiary, and quaternary structure were introduced by Kaj Ulrik Linderstrøm-Lang in his 1951 Lane Medical Lectures at Stanford University.(W)
biopolymerBiopolymers are natural polymers produced by living organisms; in other words, they are polymeric biomolecules derived from cellular or extracellular matter. Biopolymers contain monomeric units that are covalently bonded to form larger structures. There are three main classes of biopolymers, classified according to the monomeric units used and the structure of the biopolymer formed: polynucleotides,polypeptides, and polysaccharides. More specifically, polynucleotides, such as RNA and DNA, are long polymers composed of 13 or more nucleotidemonomers.Polypeptides or proteins, are short polymers of amino acids and some major examples include collagen, actin, and fibrin. The last class, polysaccharides,are often linear bonded polymeric carbohydrate structures and some examples include cellulose and alginate. Other examples of biopolymers include rubber,suberin,melanin and lignin.(W)
blood sugar regulationBlood sugar regulation is the process by which the levels of blood sugar, primarily glucose, are maintained by the body within a narrow range. This tight regulation is referred to as glucose homeostasis. Insulin, which lowers blood sugar, and glucagon, which raises it, are the most well known of the hormones involved, but more recent discoveries of other glucoregulatory hormones have expanded the understanding of this process.The gland called pancreas secrete two hormones and they are primarily responsible to regulate glucose levels in blood. (W)
The flat line is the optimal blood sugar level (i.e. the homeostatic set point). Blood sugar levels are balanced by the tug-of-war between 2 functionally opposite hormones, glucagon and insulin.
Blood glucose levels are maintained at a constant level in the body by a negative feedback mechanism. When the blood glucose level is too high, the pancreas secretes insulin and when the level is too low, the pancreas then secretes glucagon. The flat line shown represents the homeostatic set point. The sinusoidal line represents the blood glucose level.
bond, bonding → chemical bond
bZIP domain
The Basic Leucine Zipper Domain (bZIP domain) is found in many DNA binding eukaryotic proteins. One part of the domain contains a region that mediates sequence specific DNA binding properties and the leucine zipper that is required to hold together (dimerize) two DNA binding regions. The DNA binding region comprises a number of basic amino acids such as arginine and lysine. Proteins containing this domain are transcription factors. (W)
Leucine zipper: CREB-1 binding to DNA. Data used from 1dh3. The magnesium ion is colored in green.

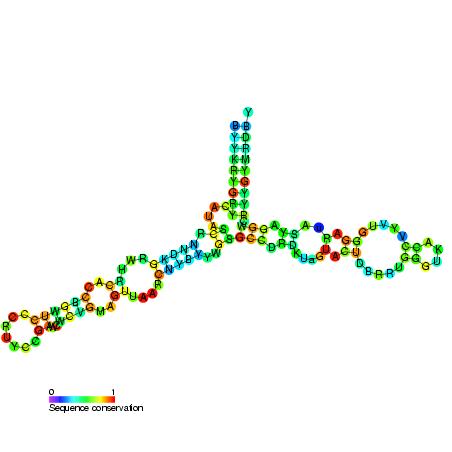
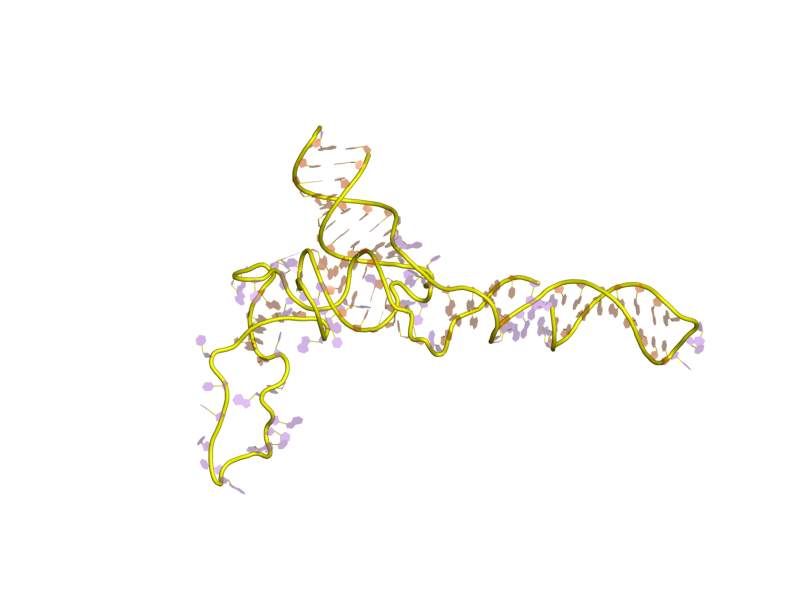
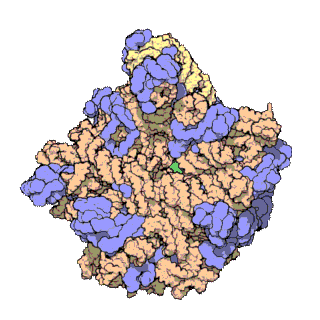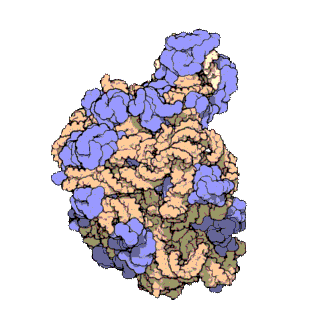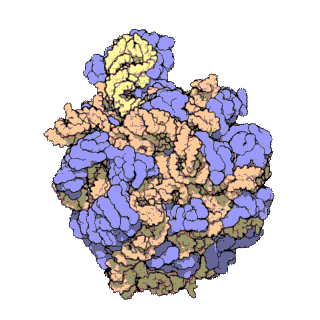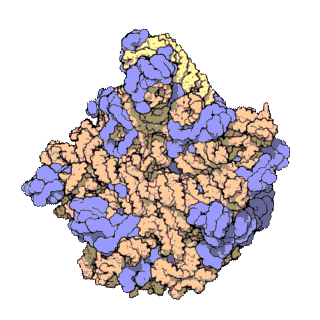
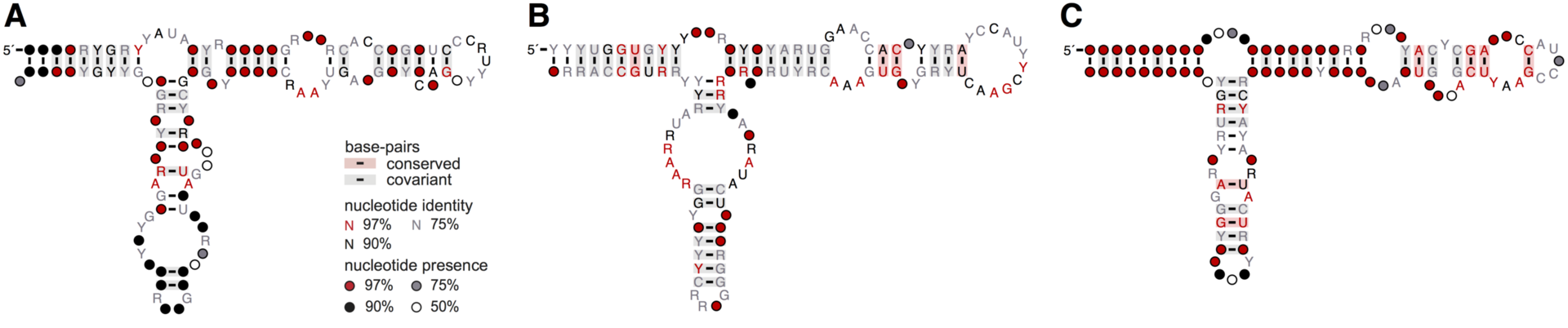
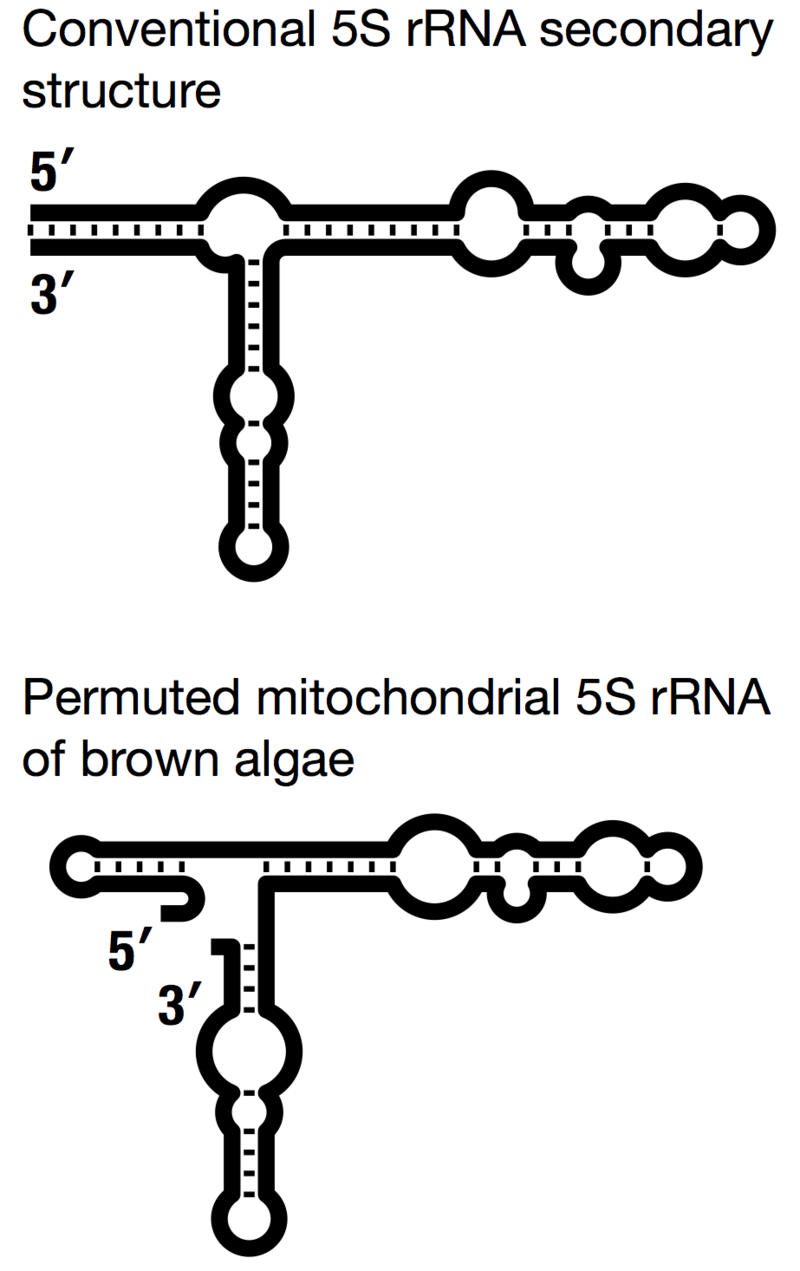
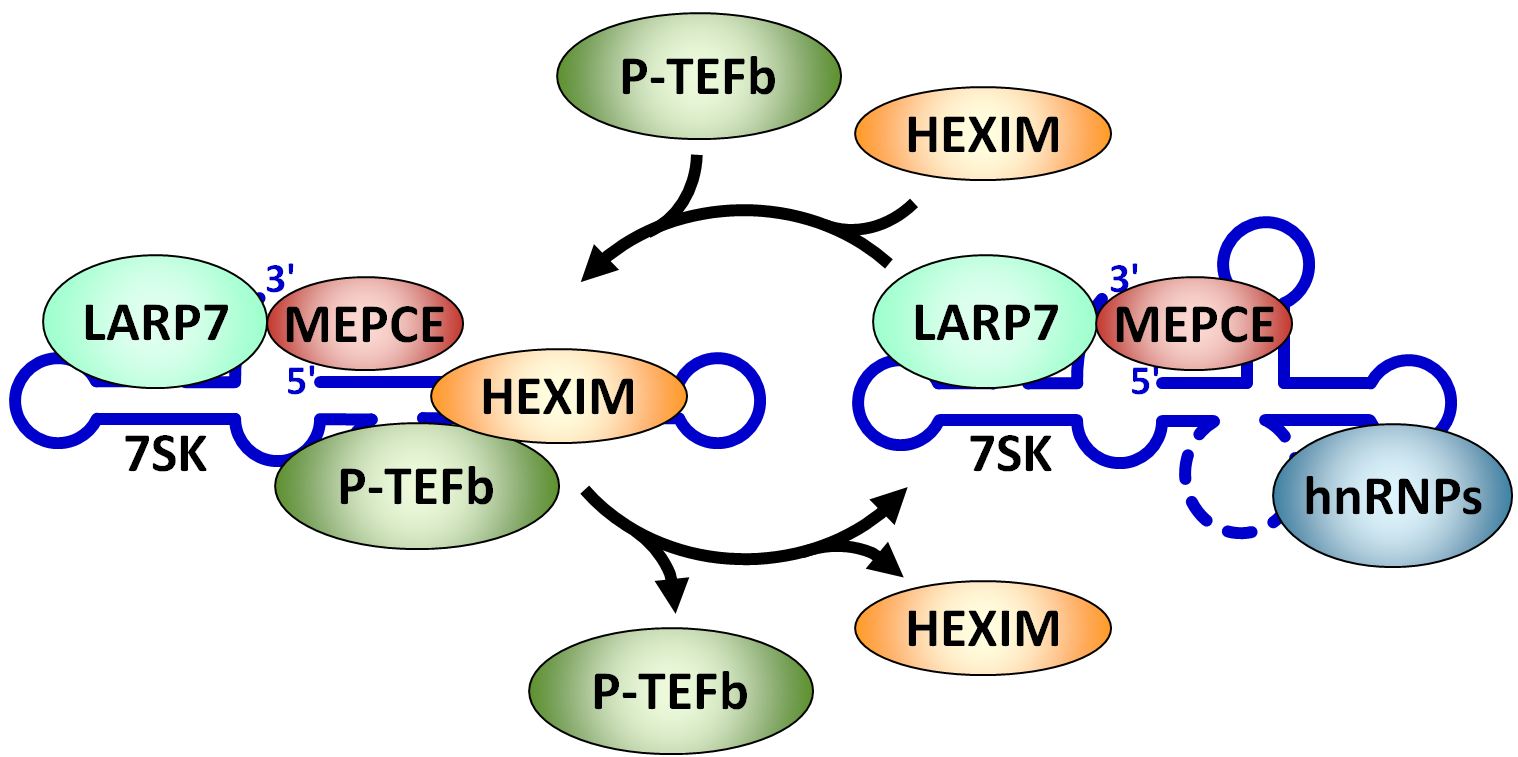
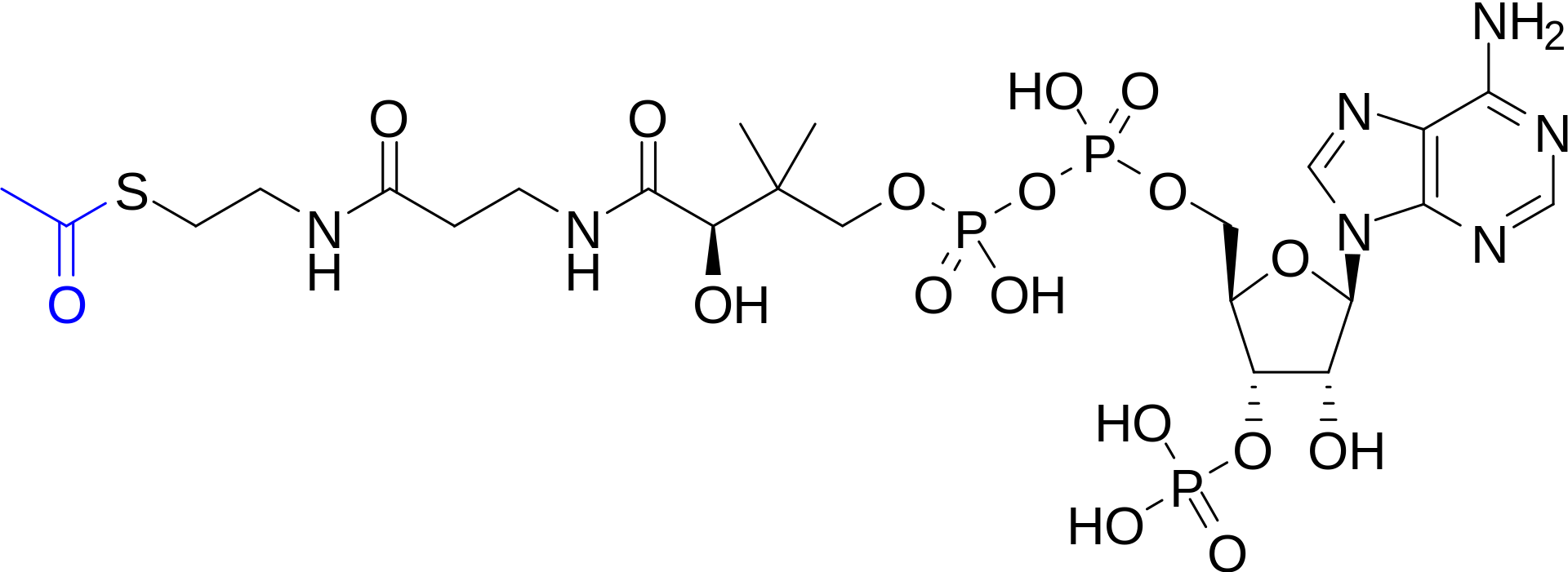
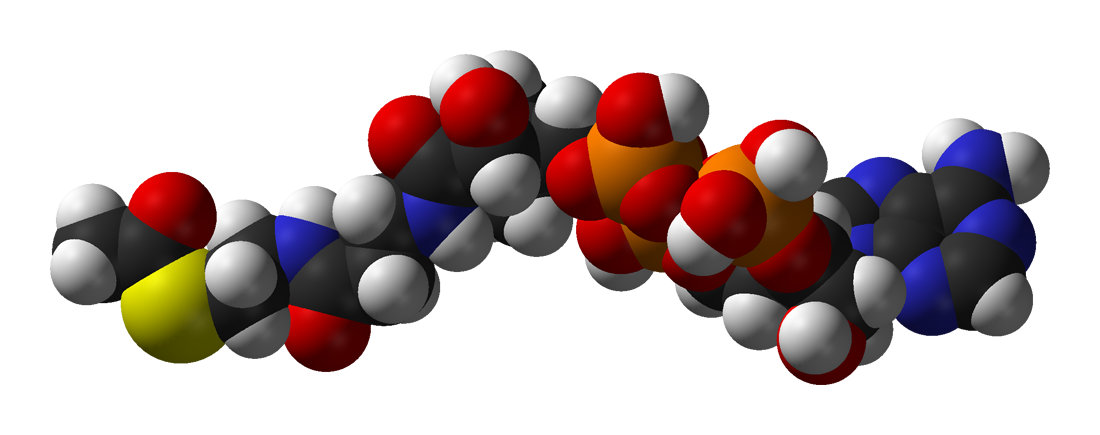


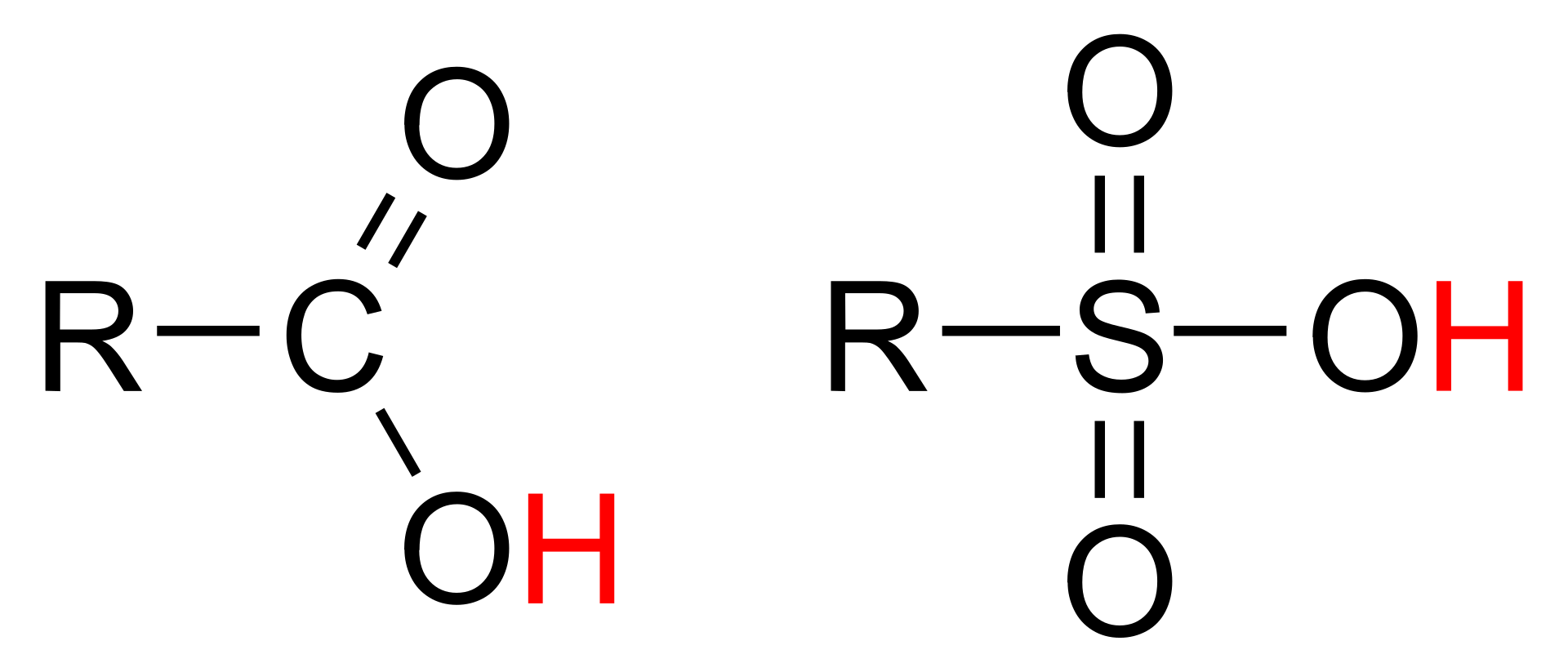
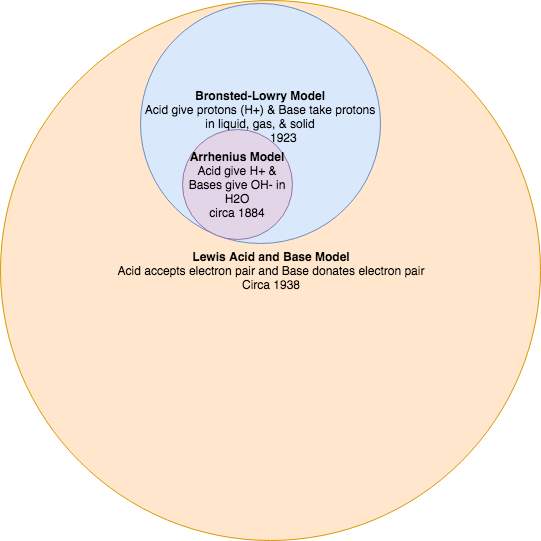
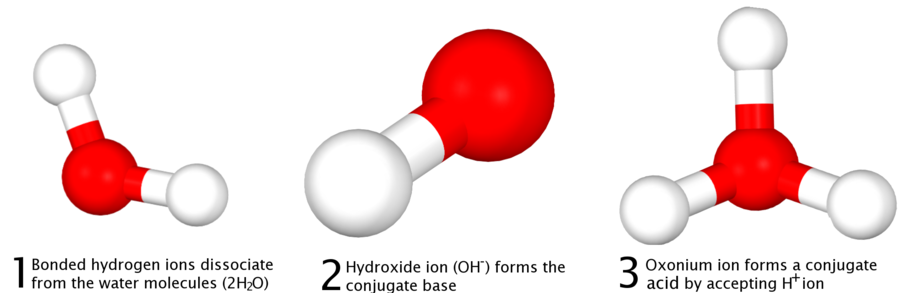
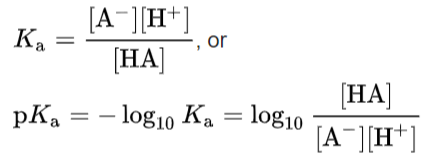
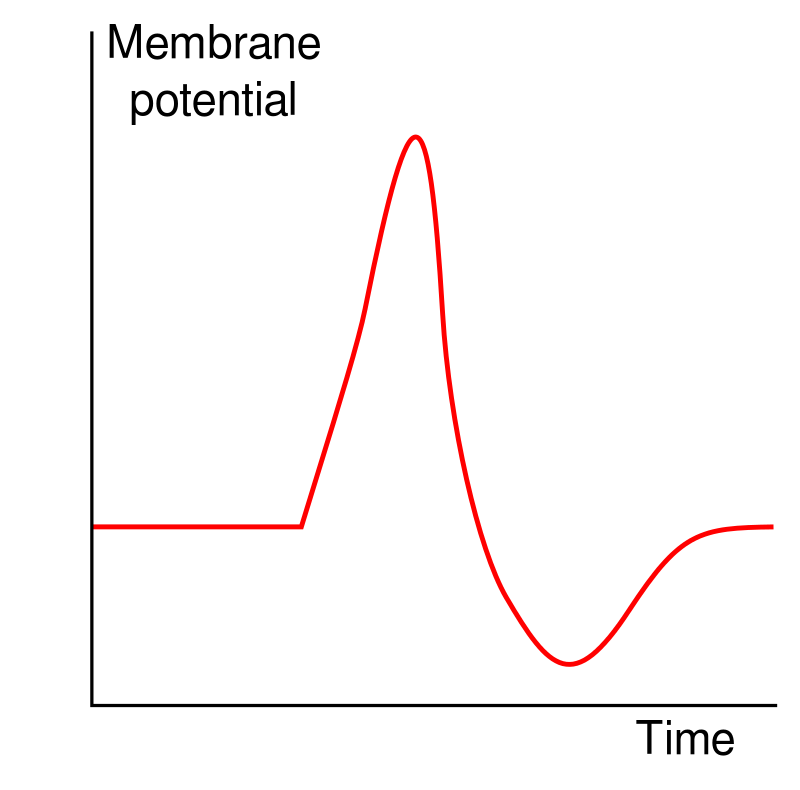
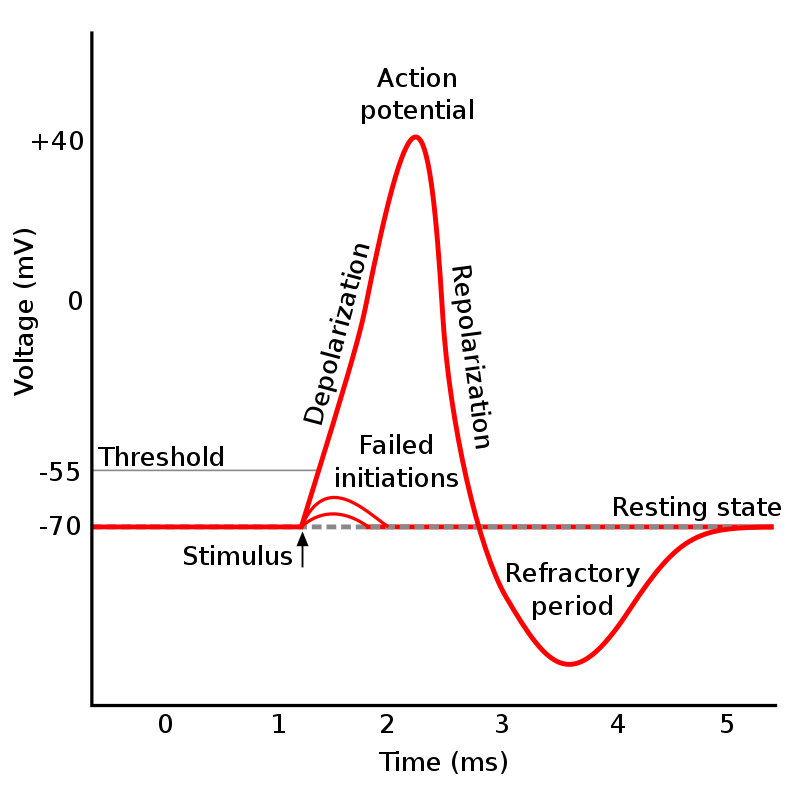
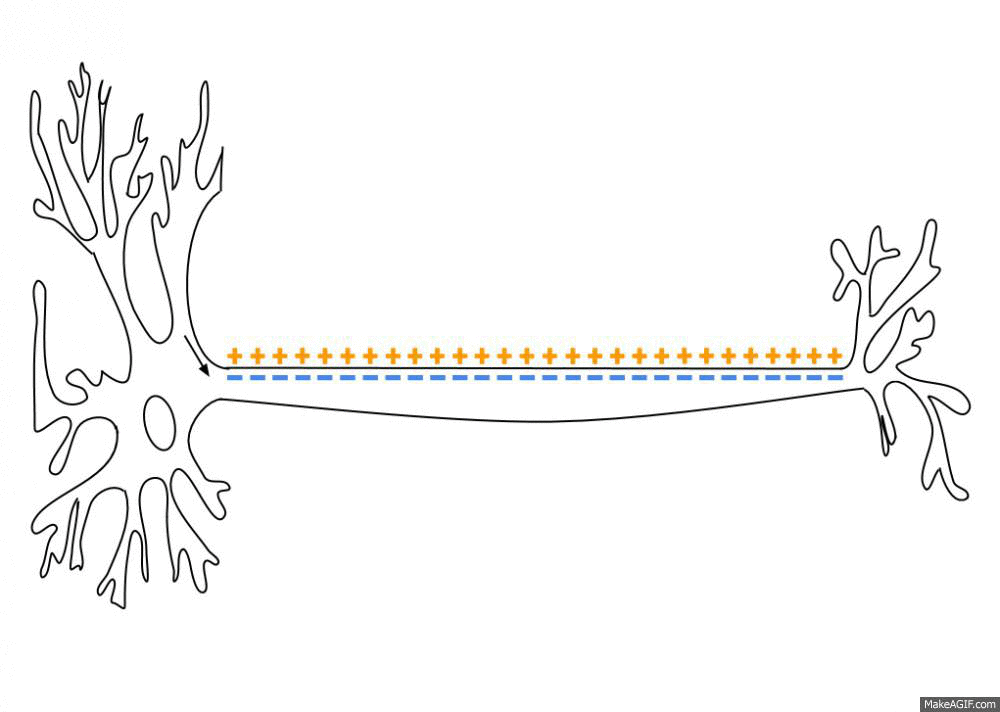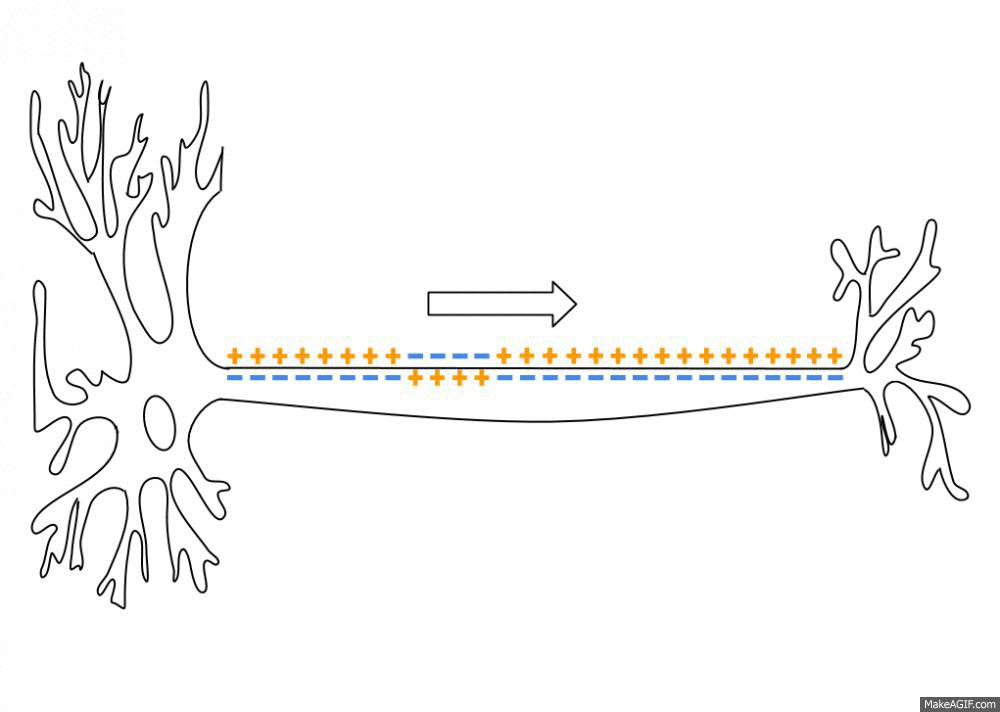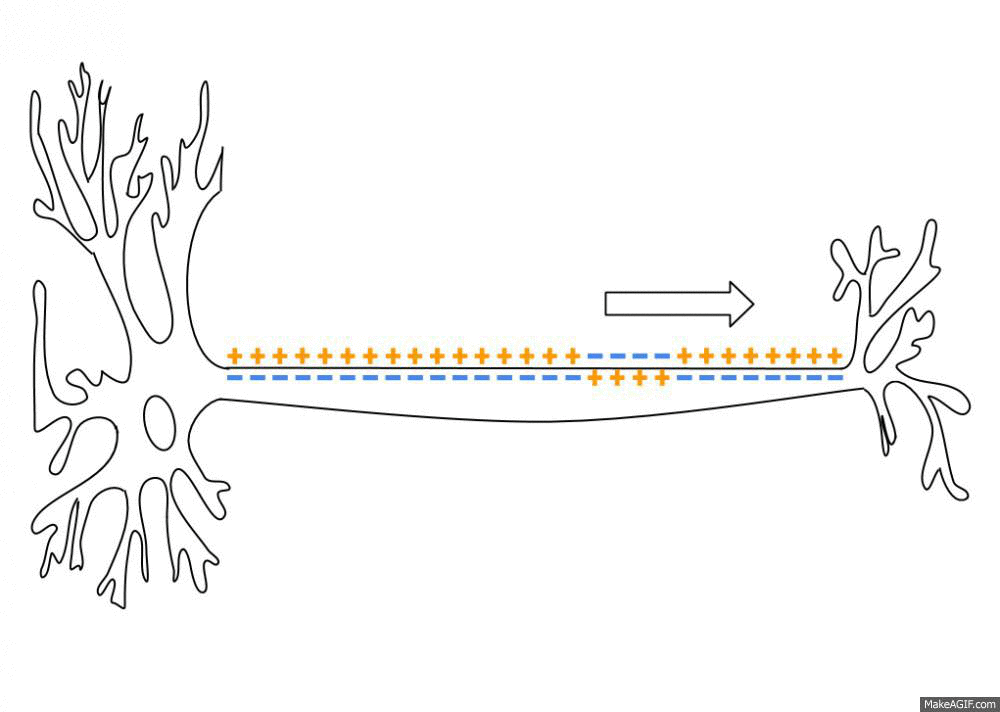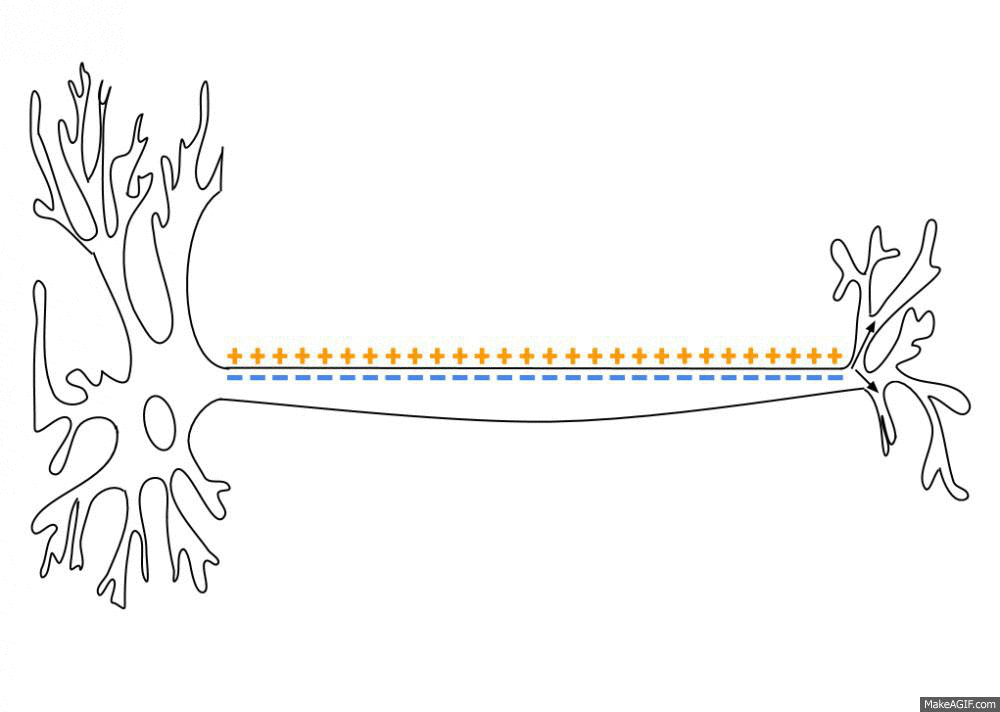
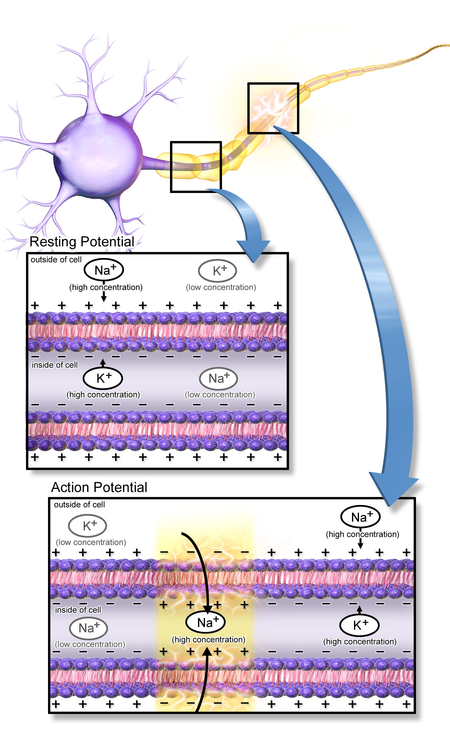
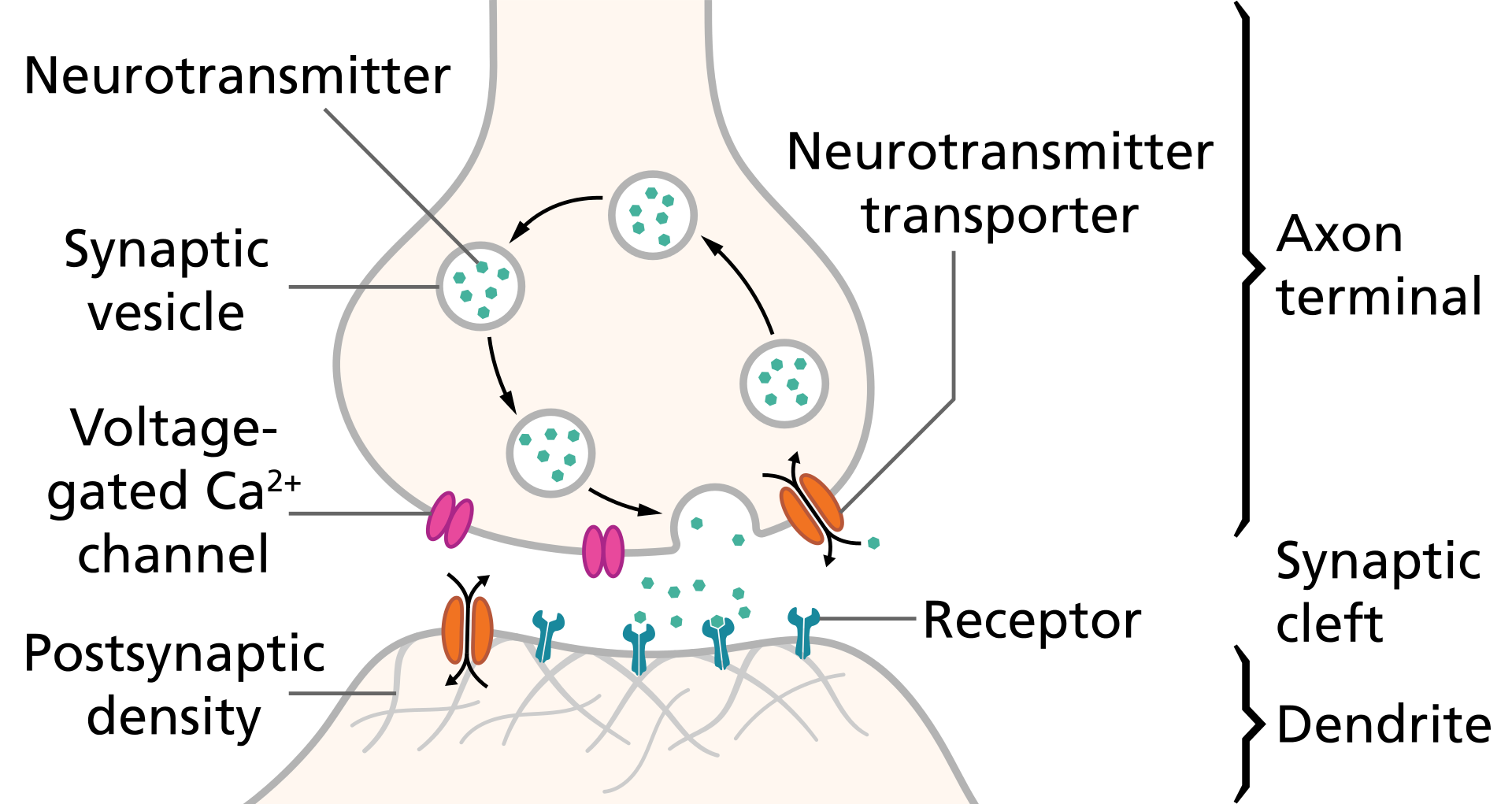
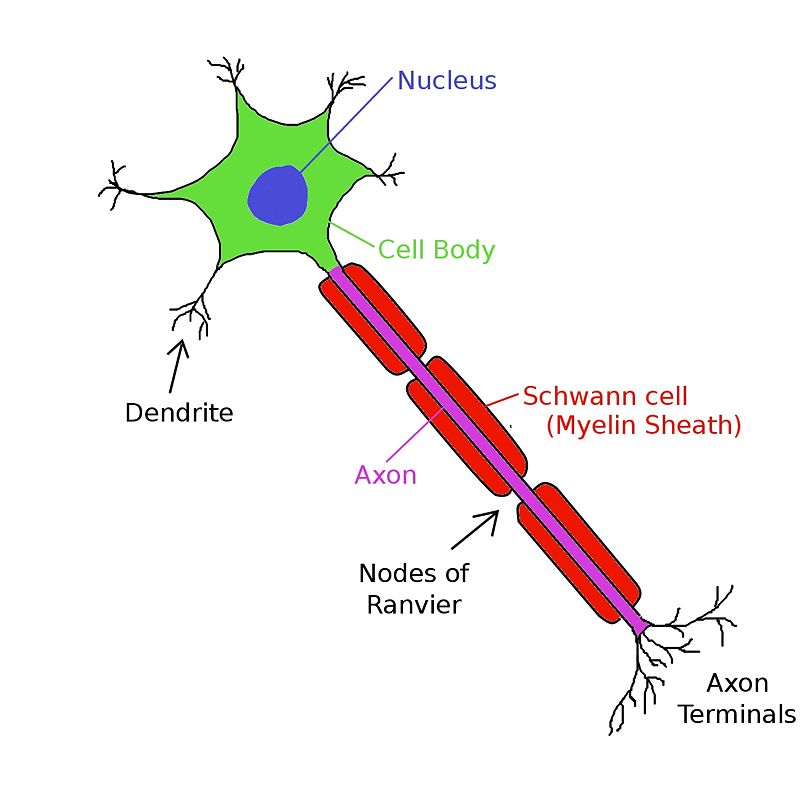
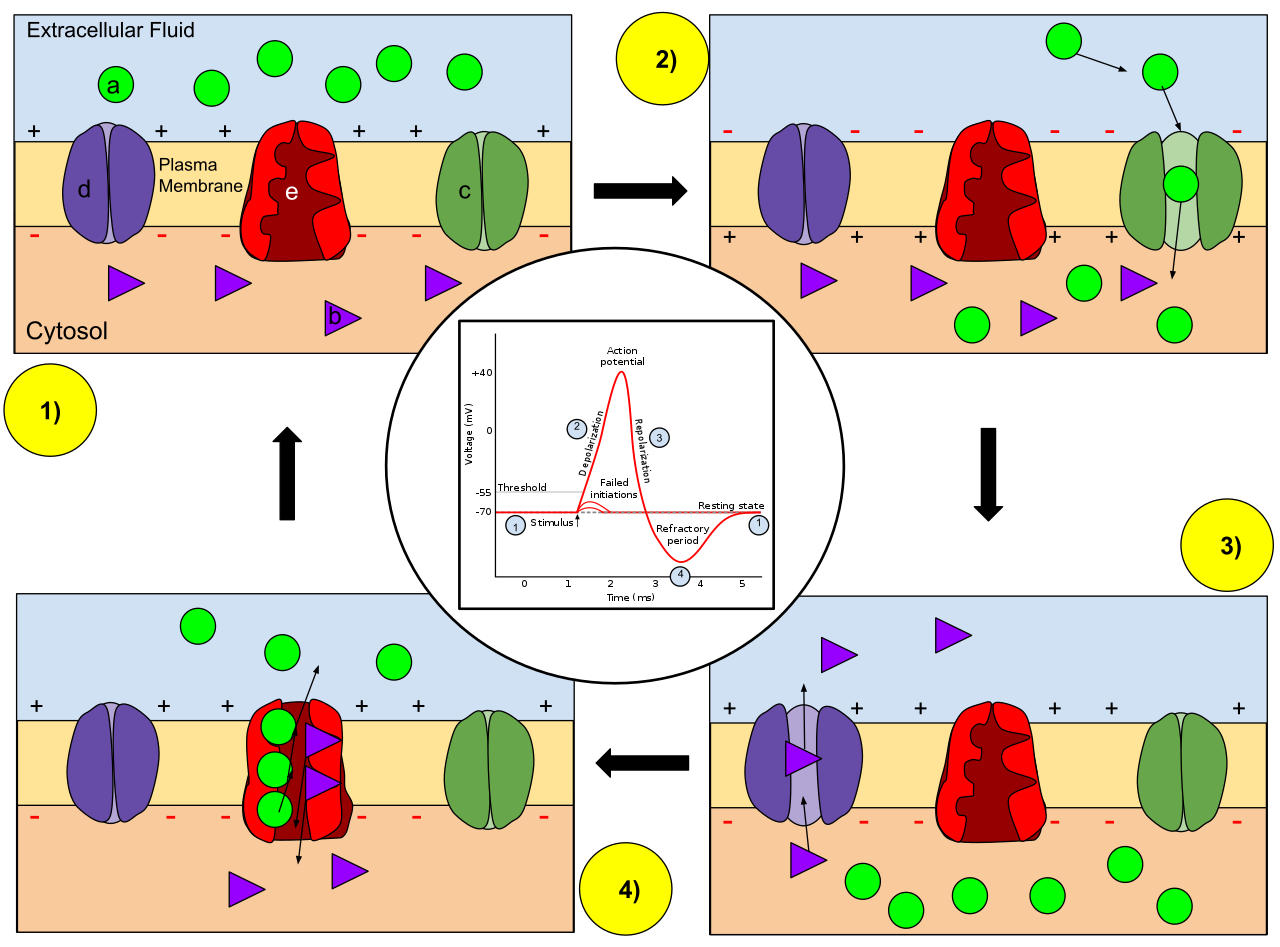
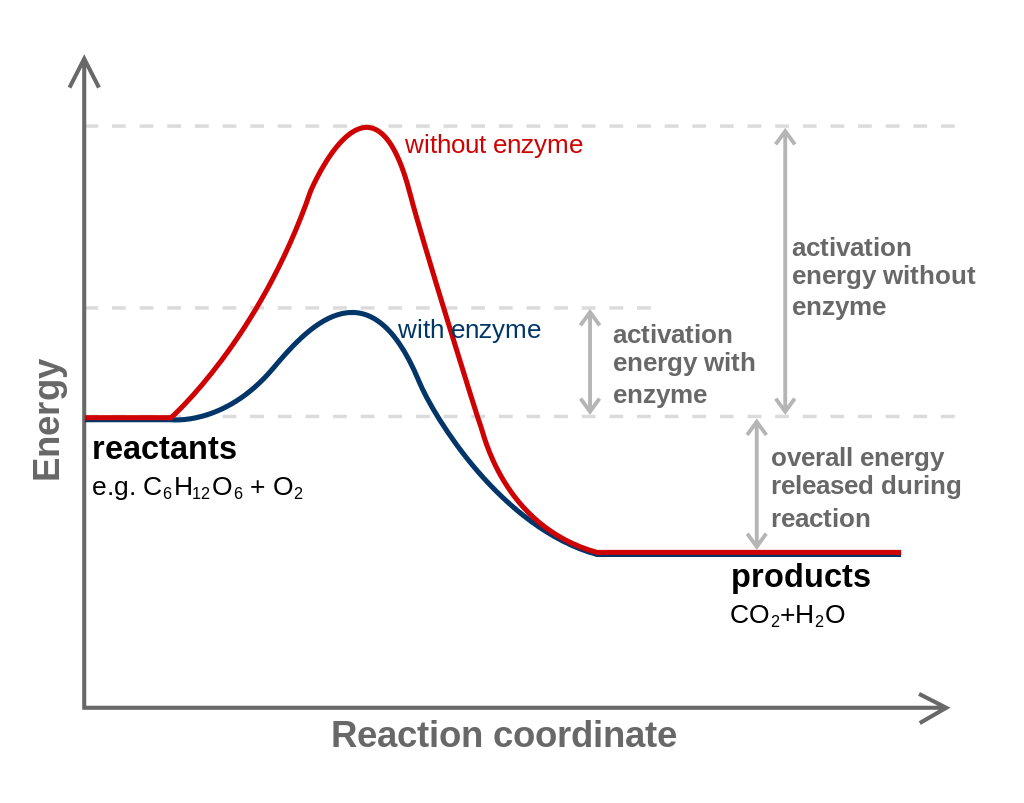
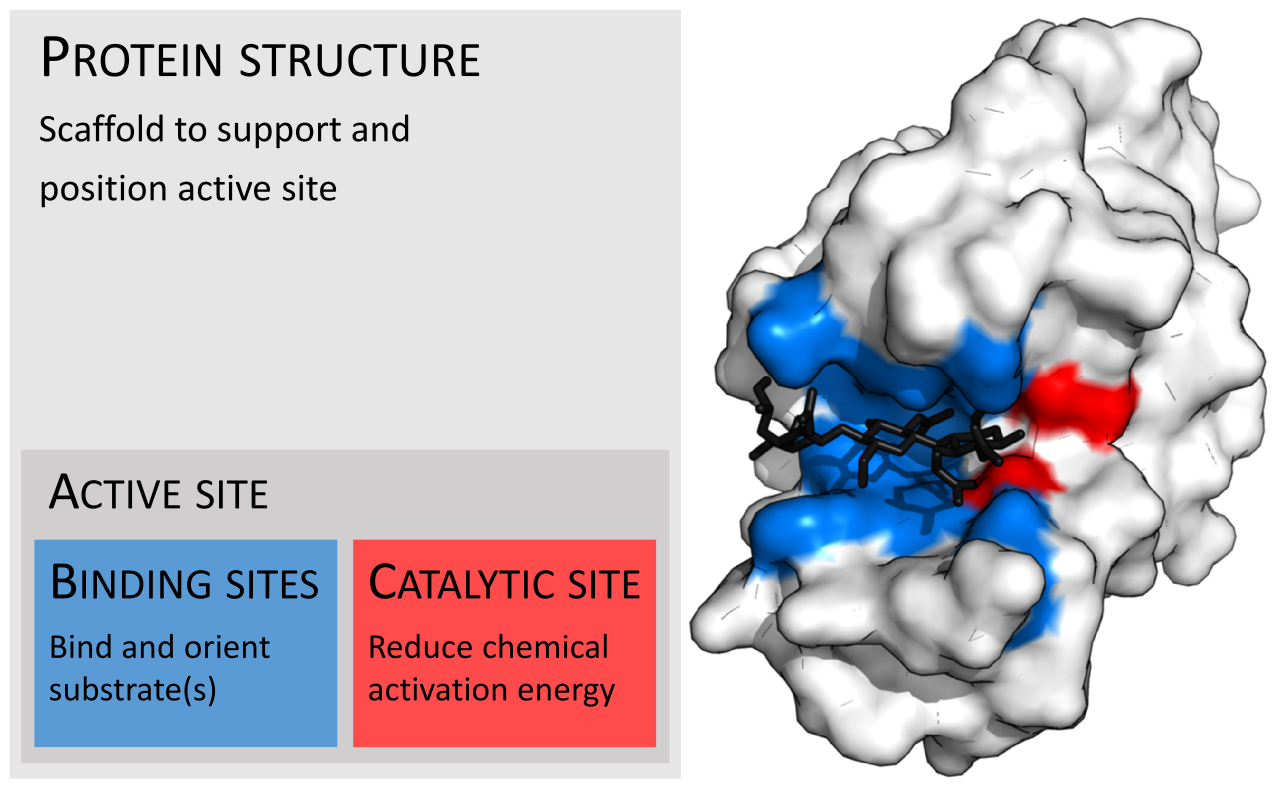
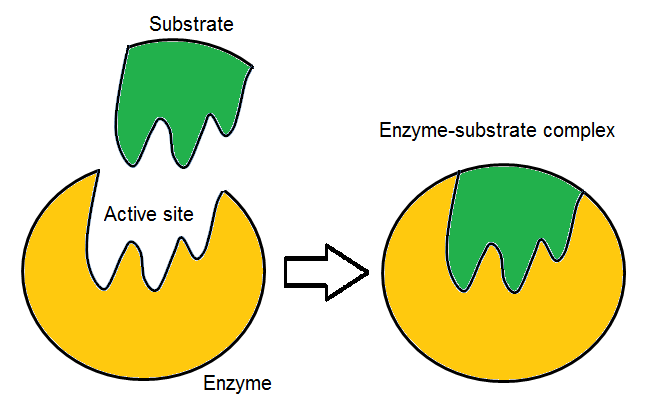
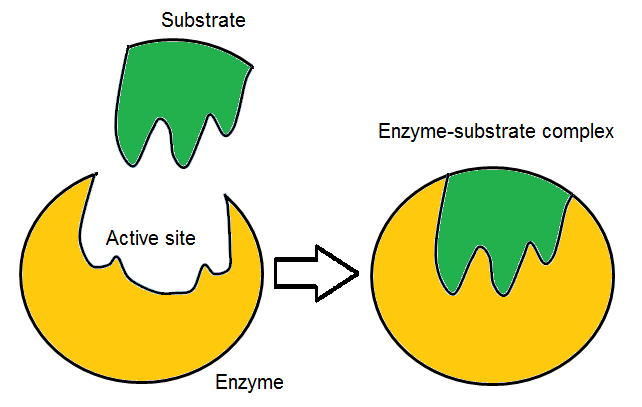
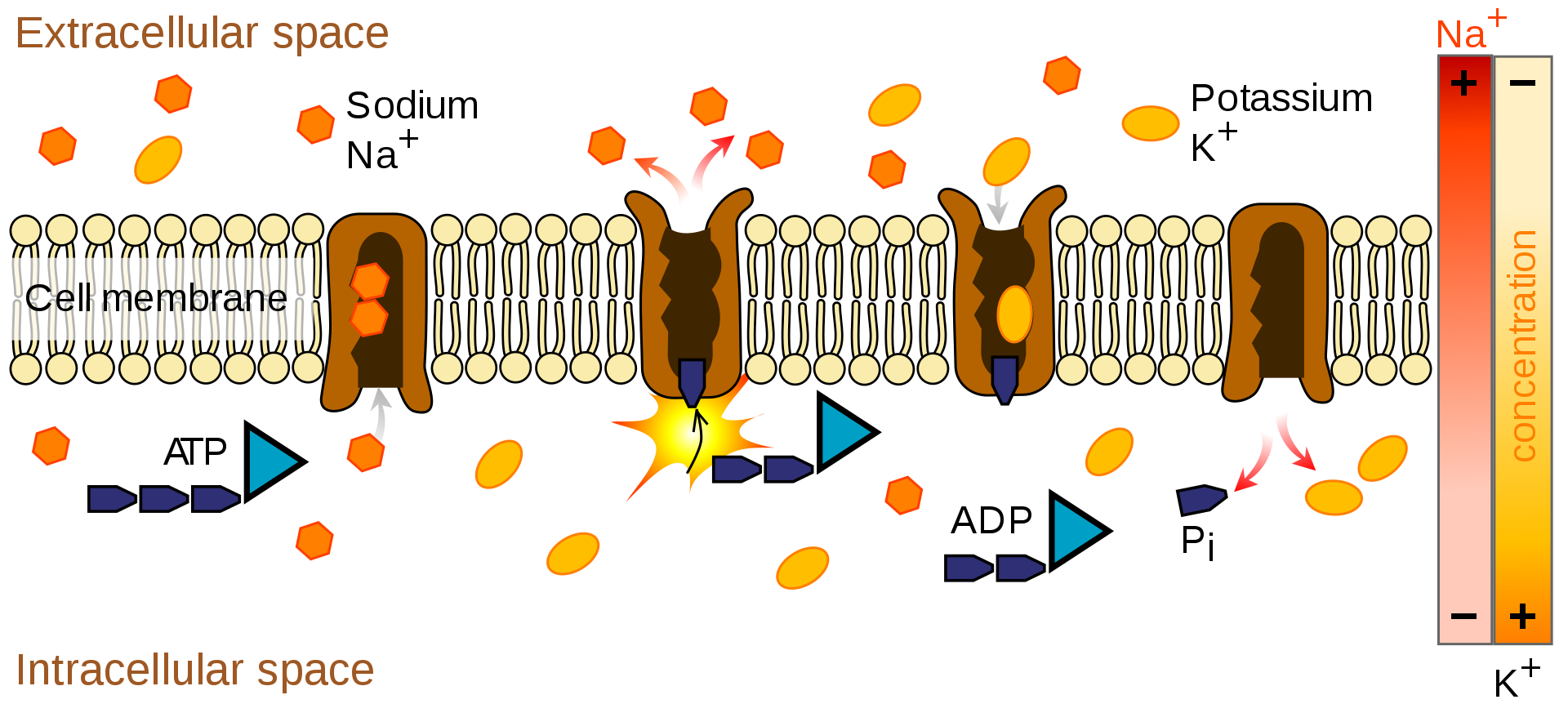
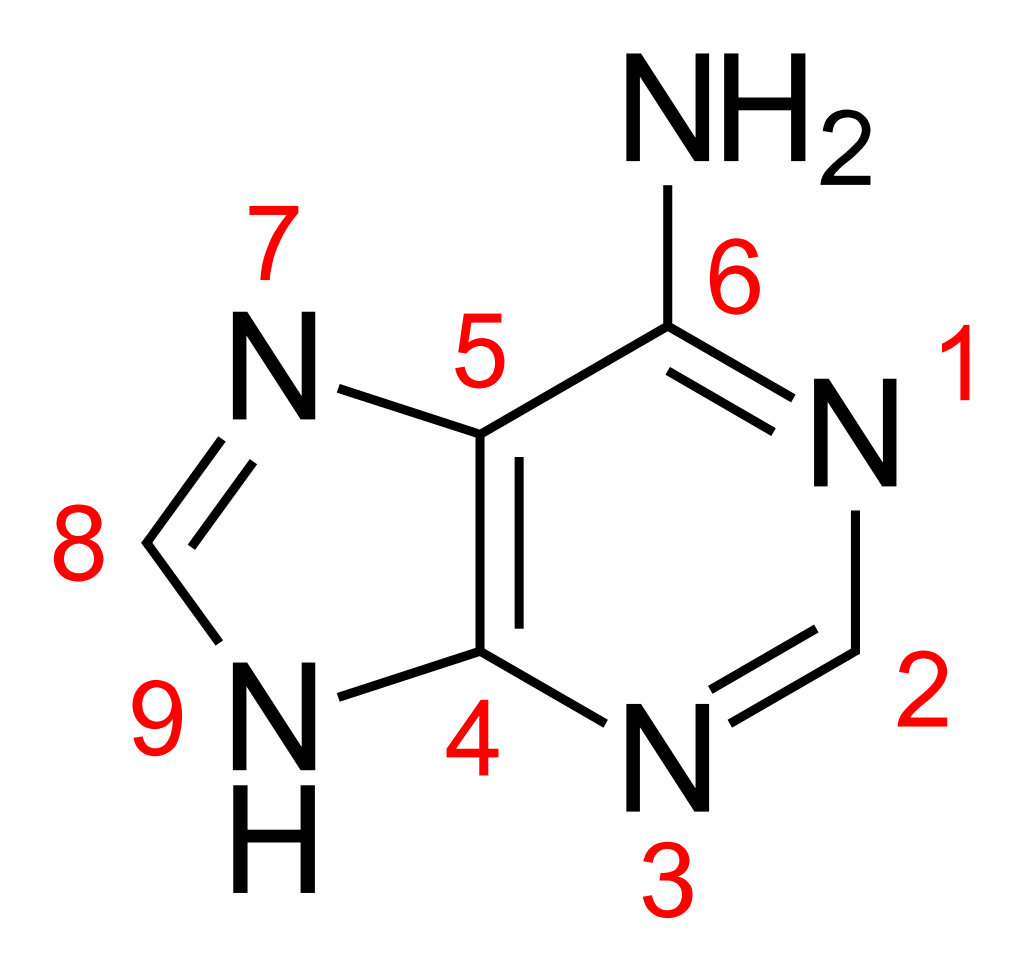
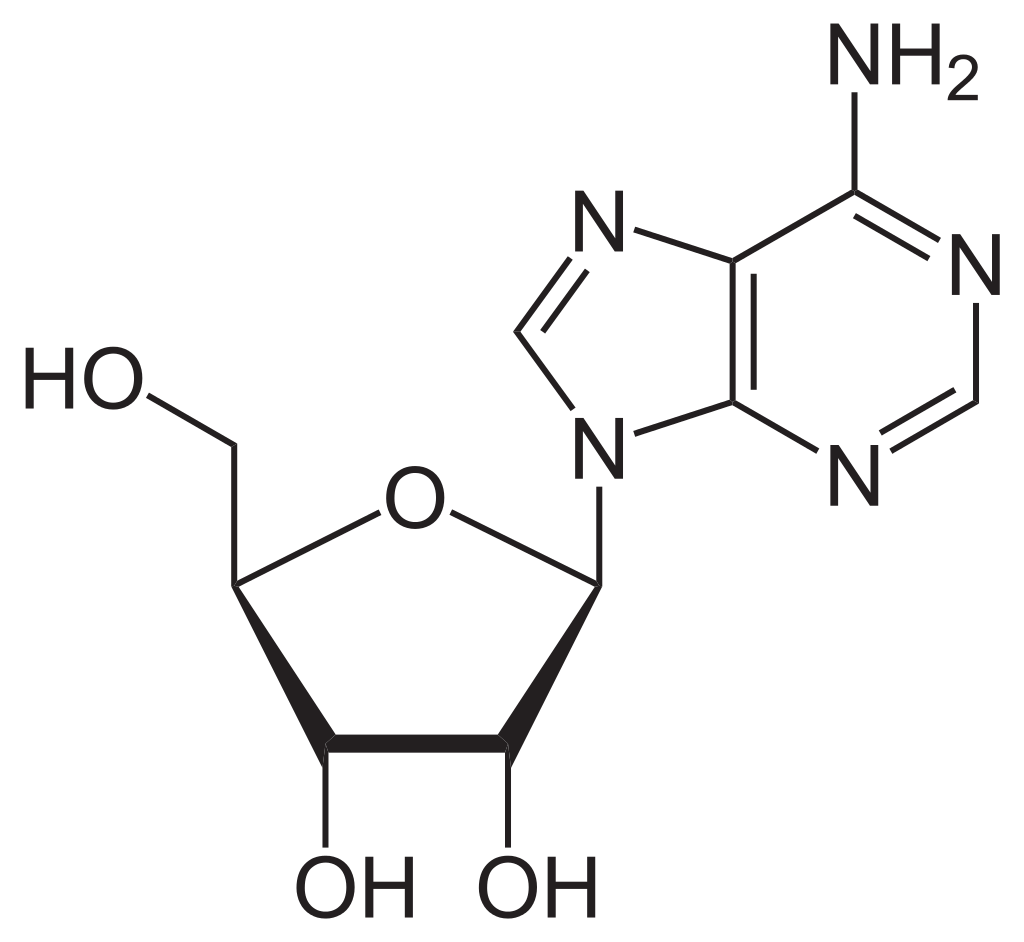
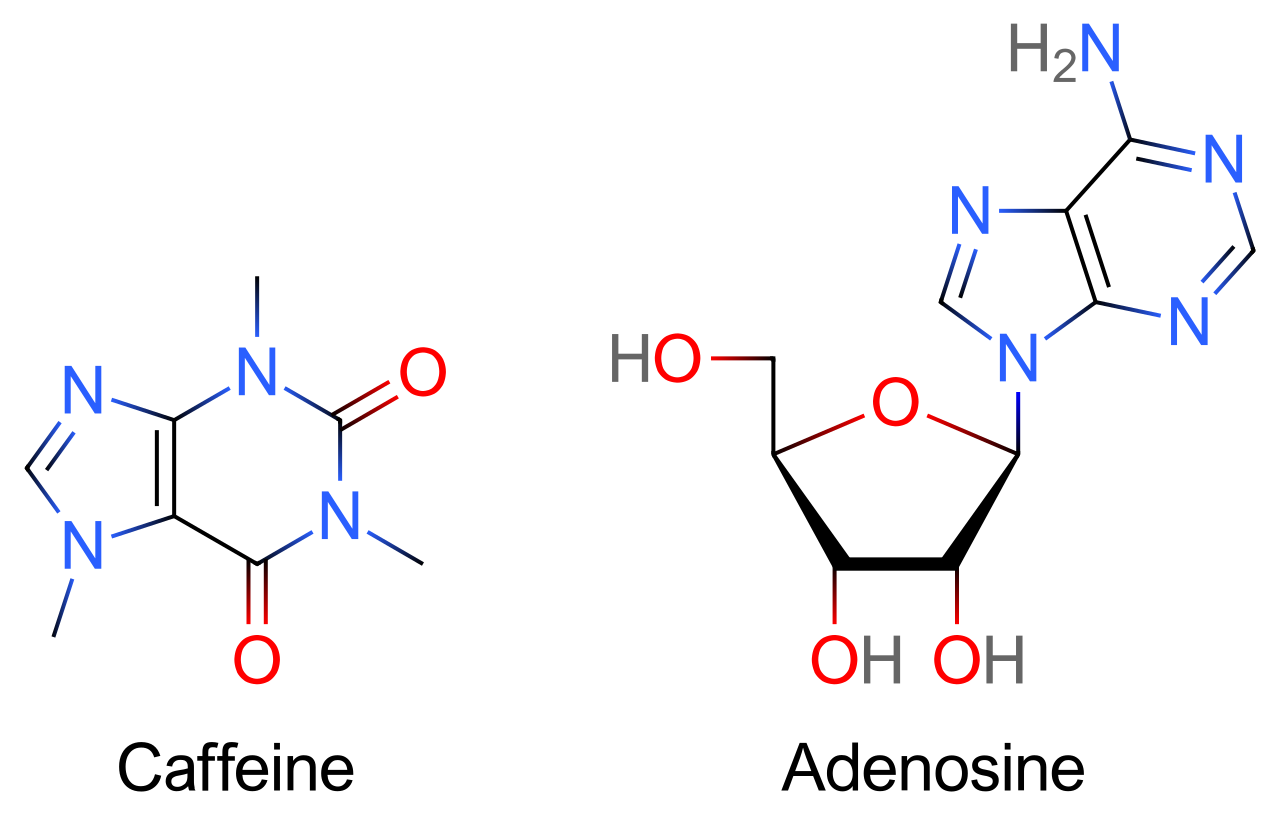
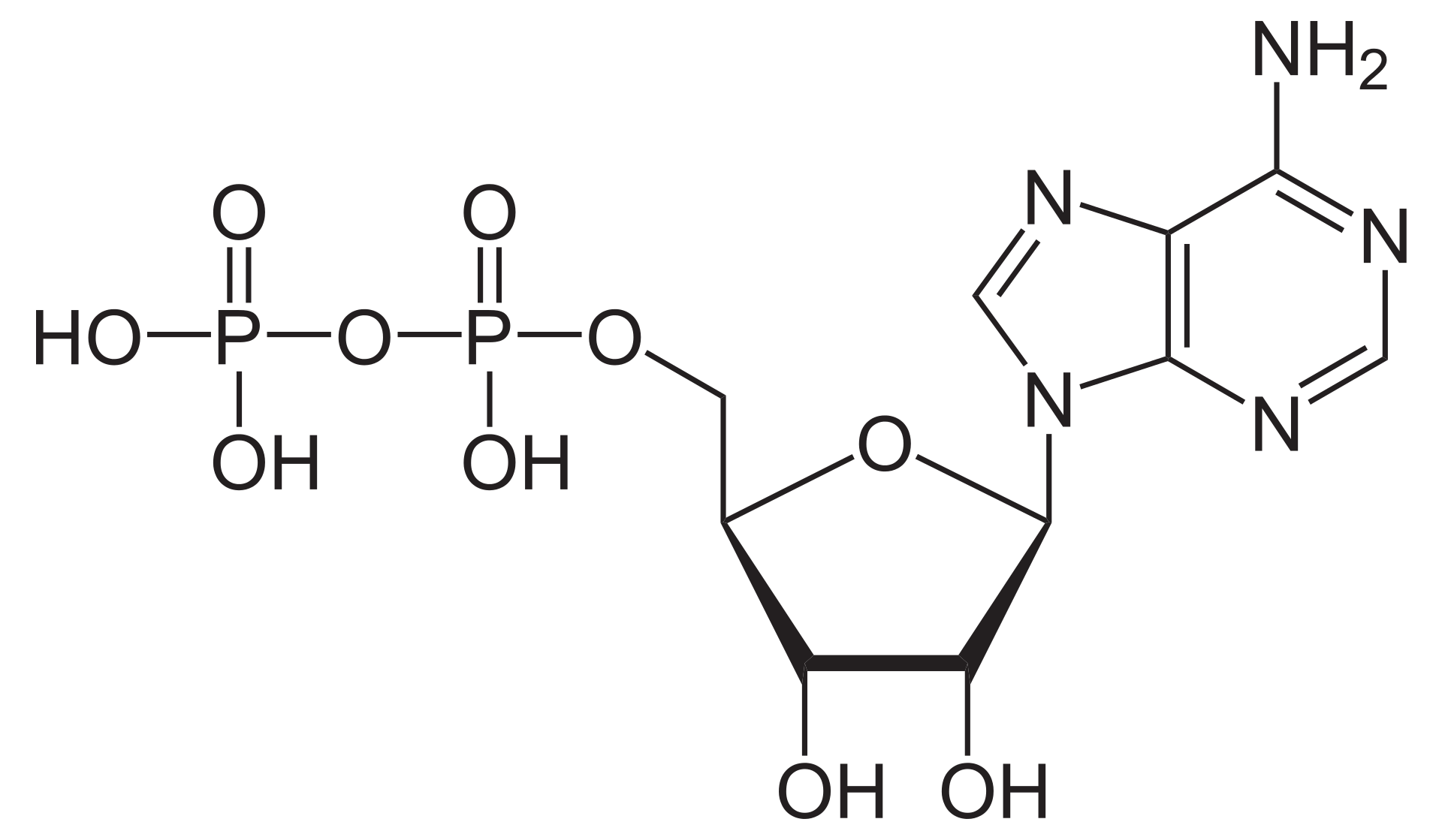
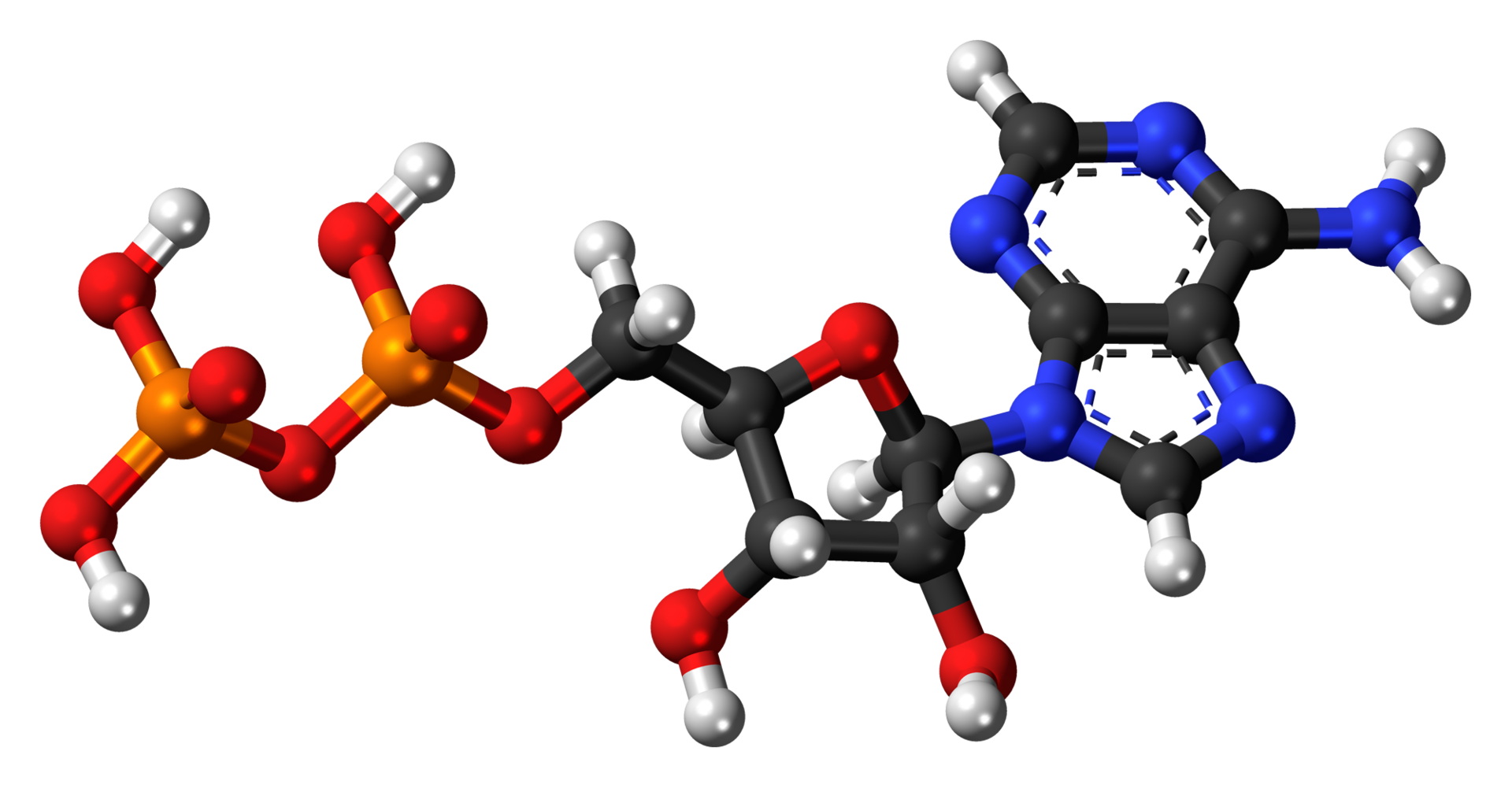
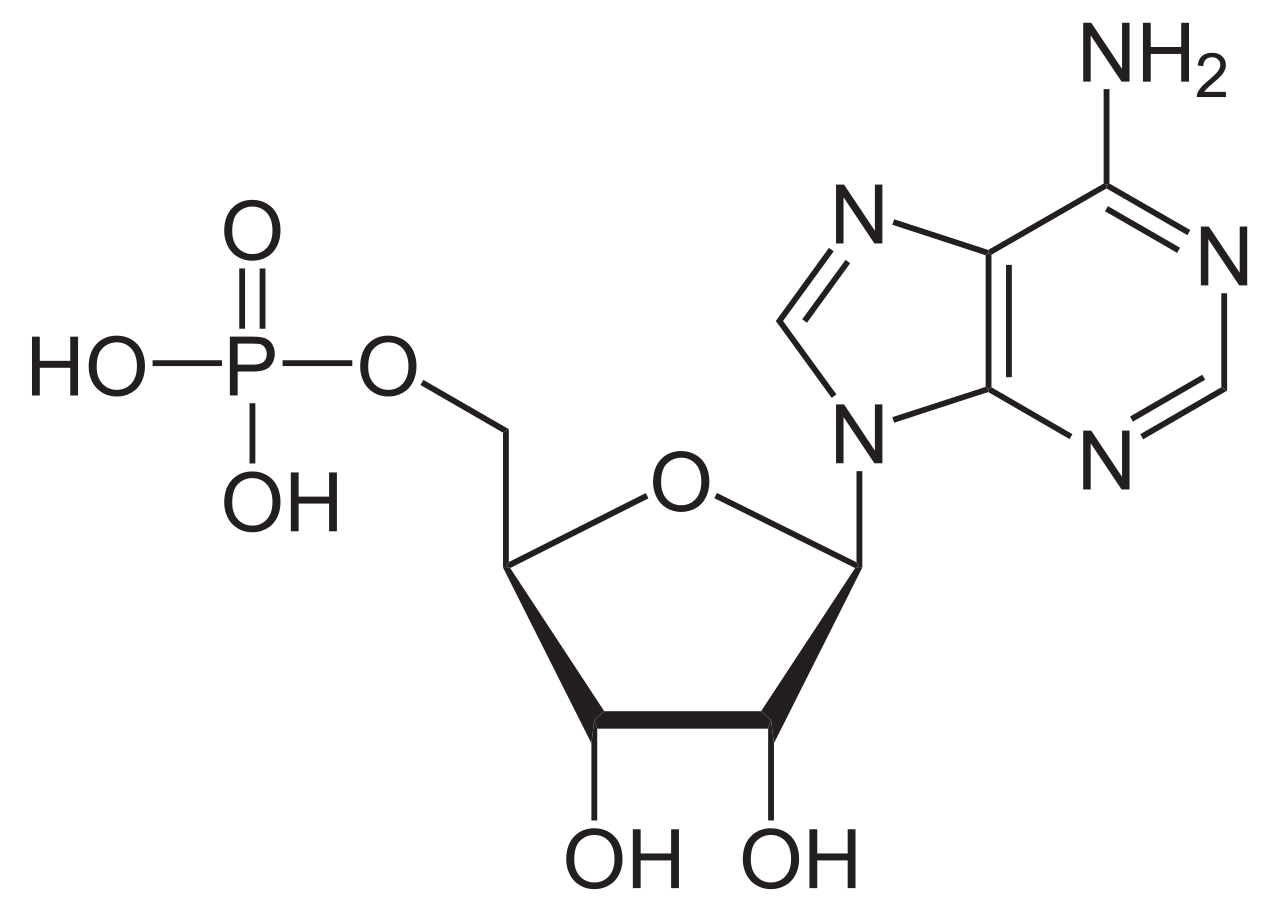
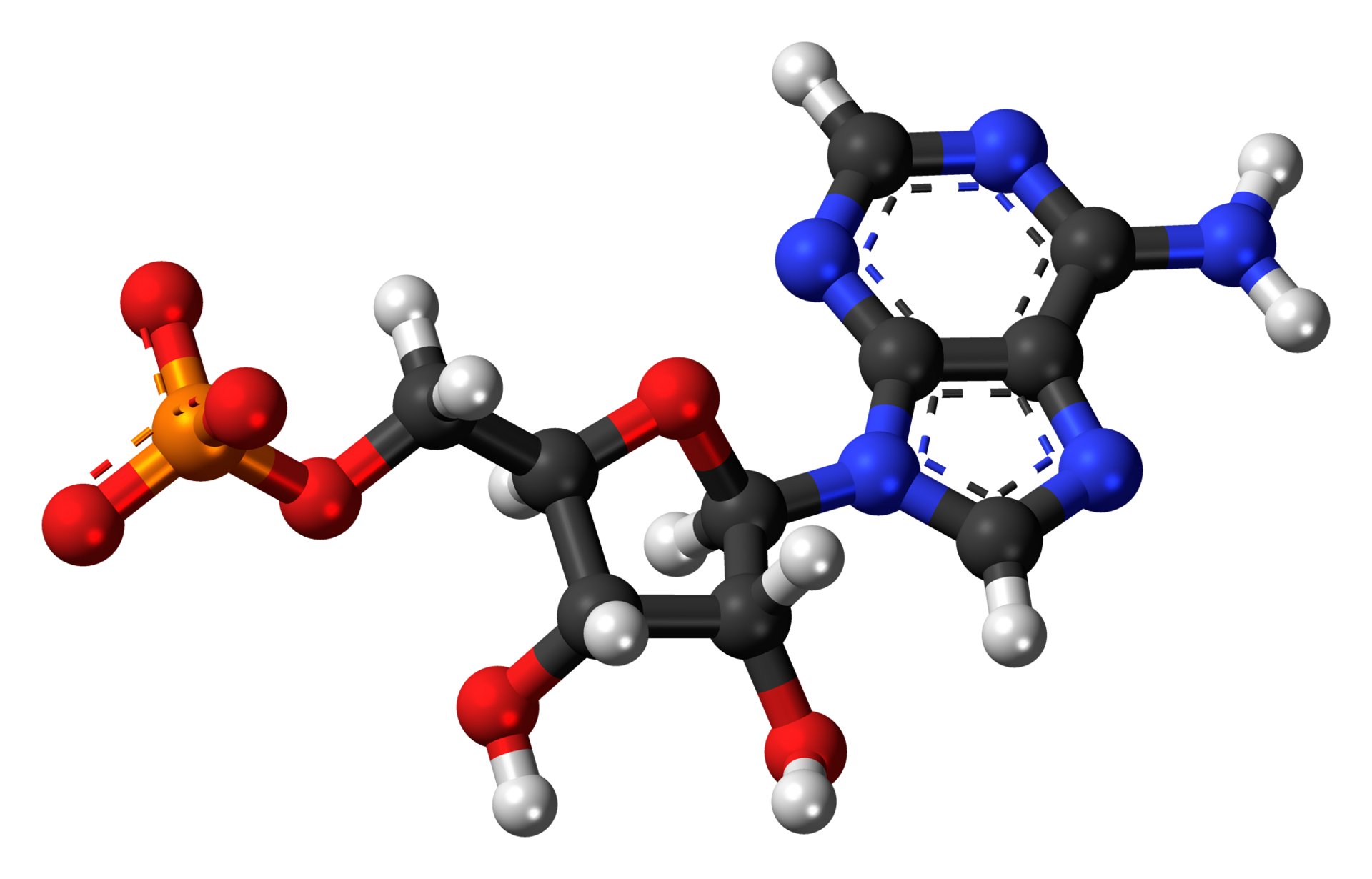
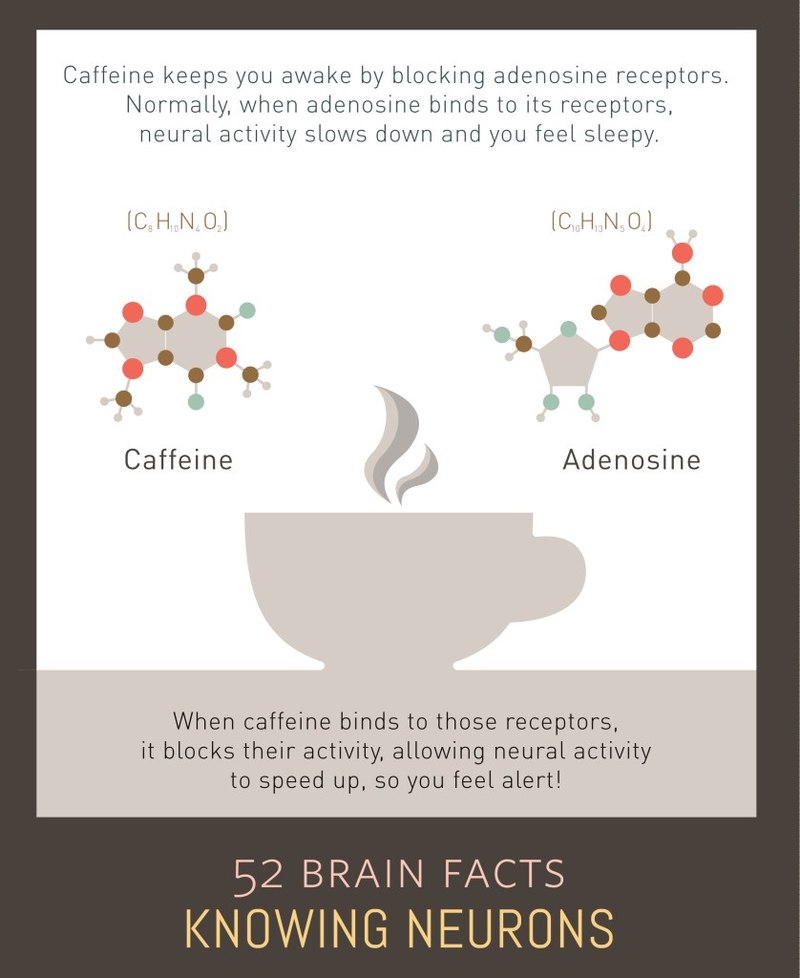
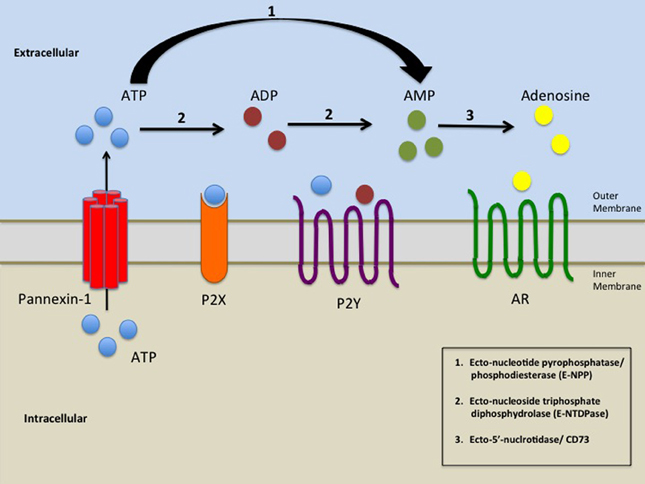
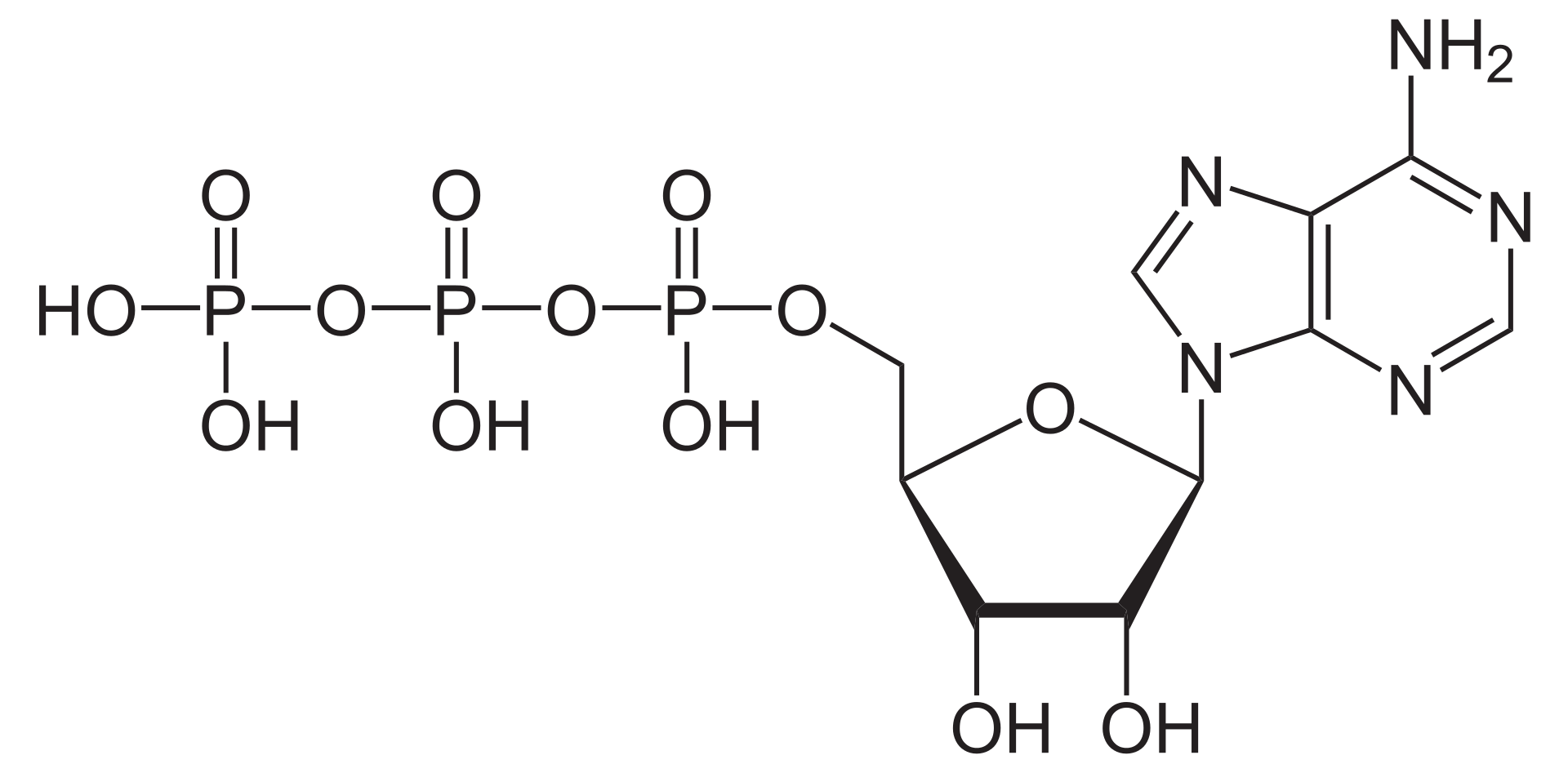
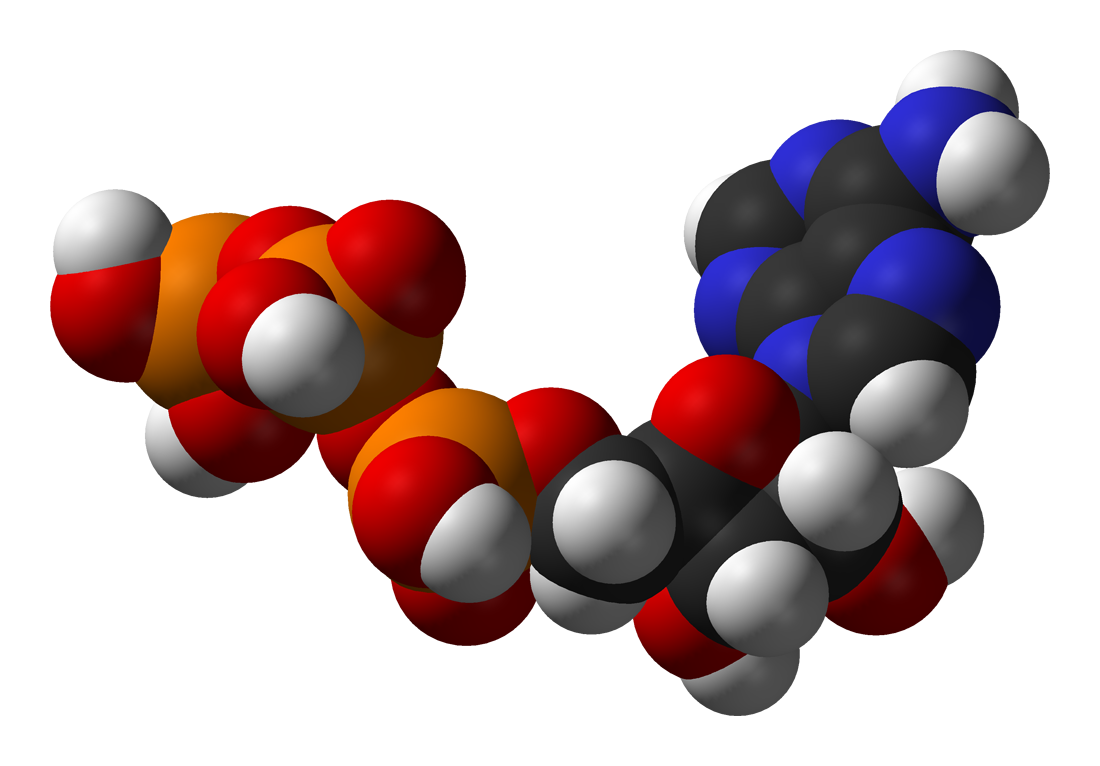
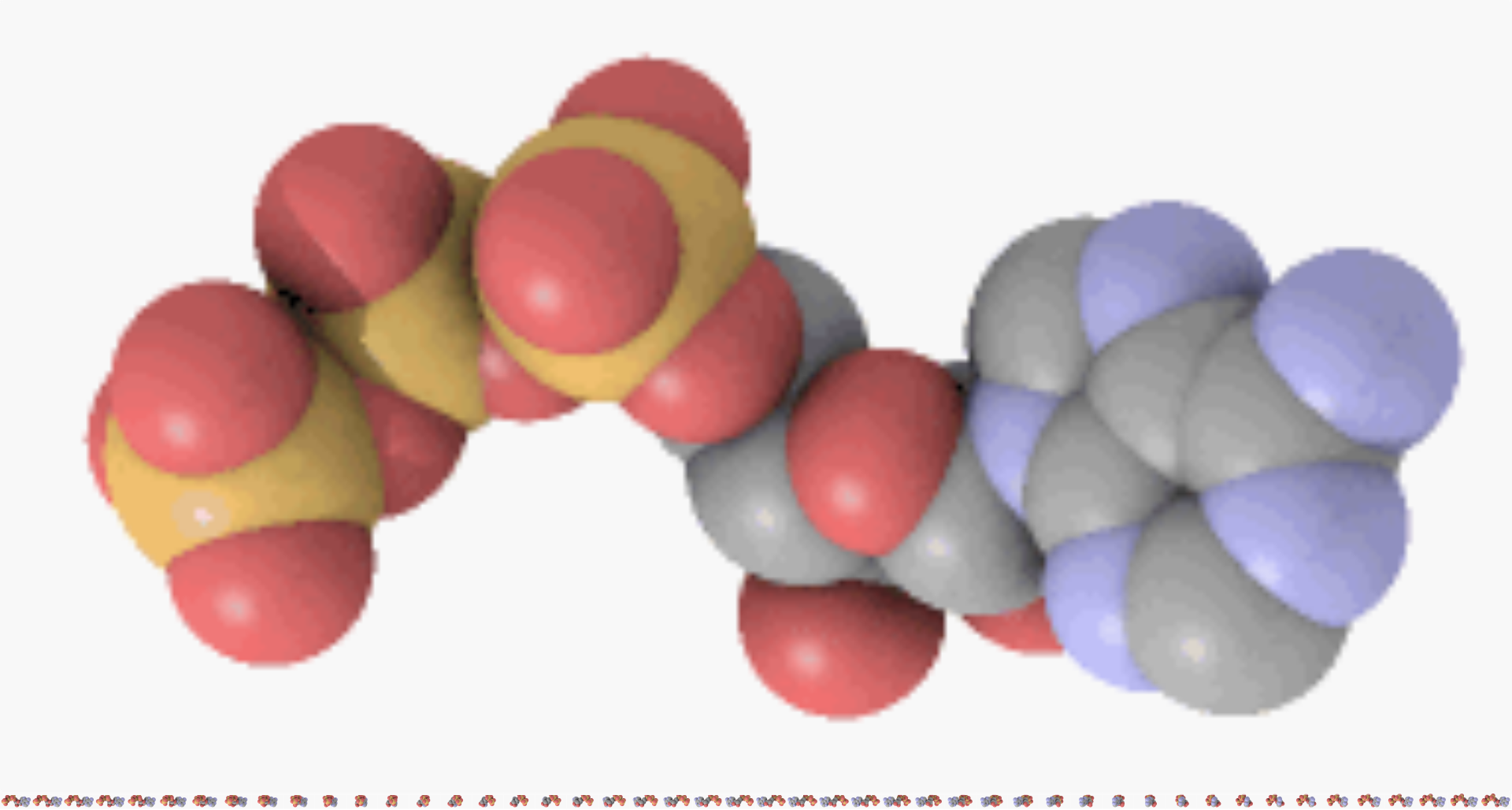
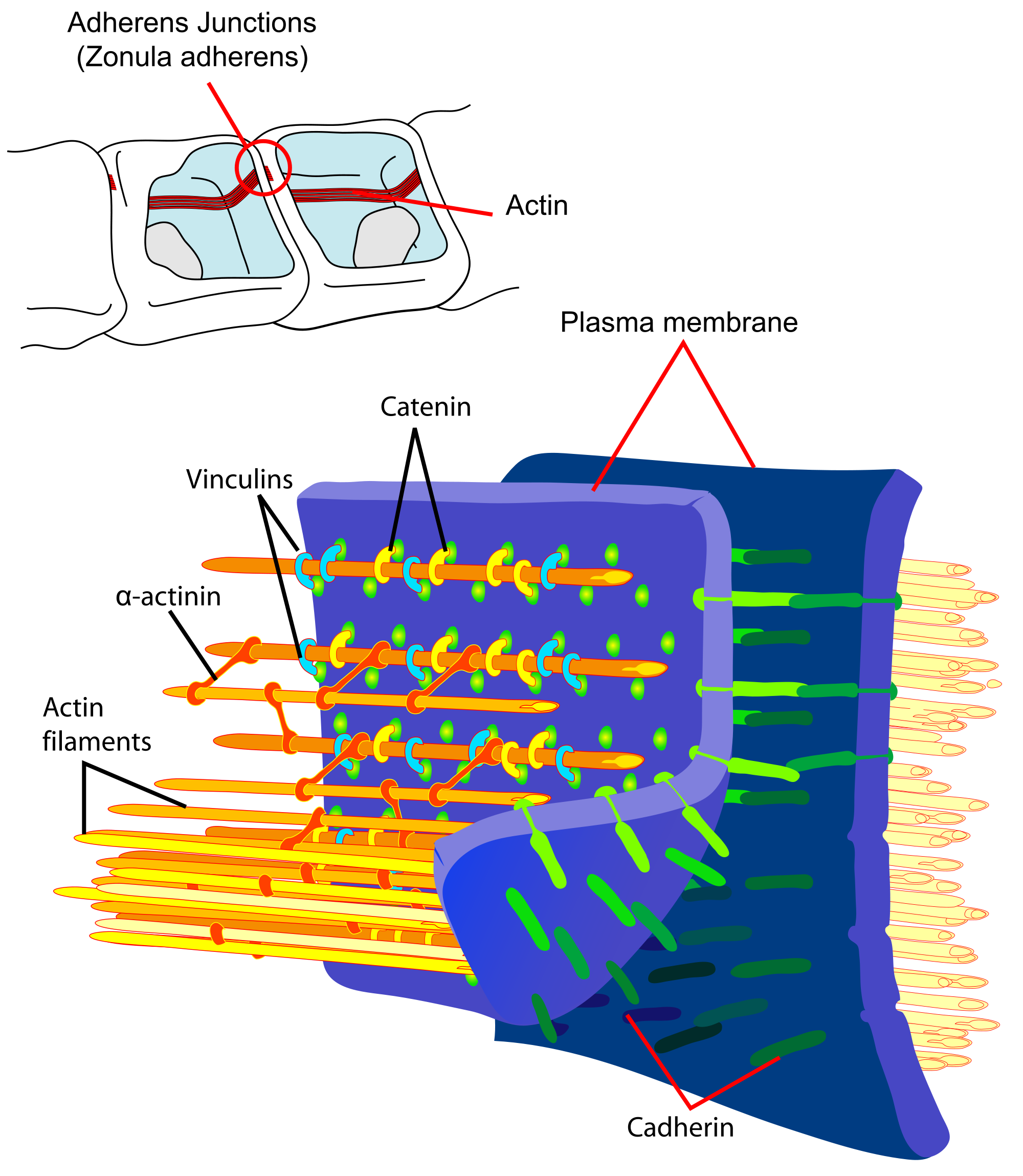
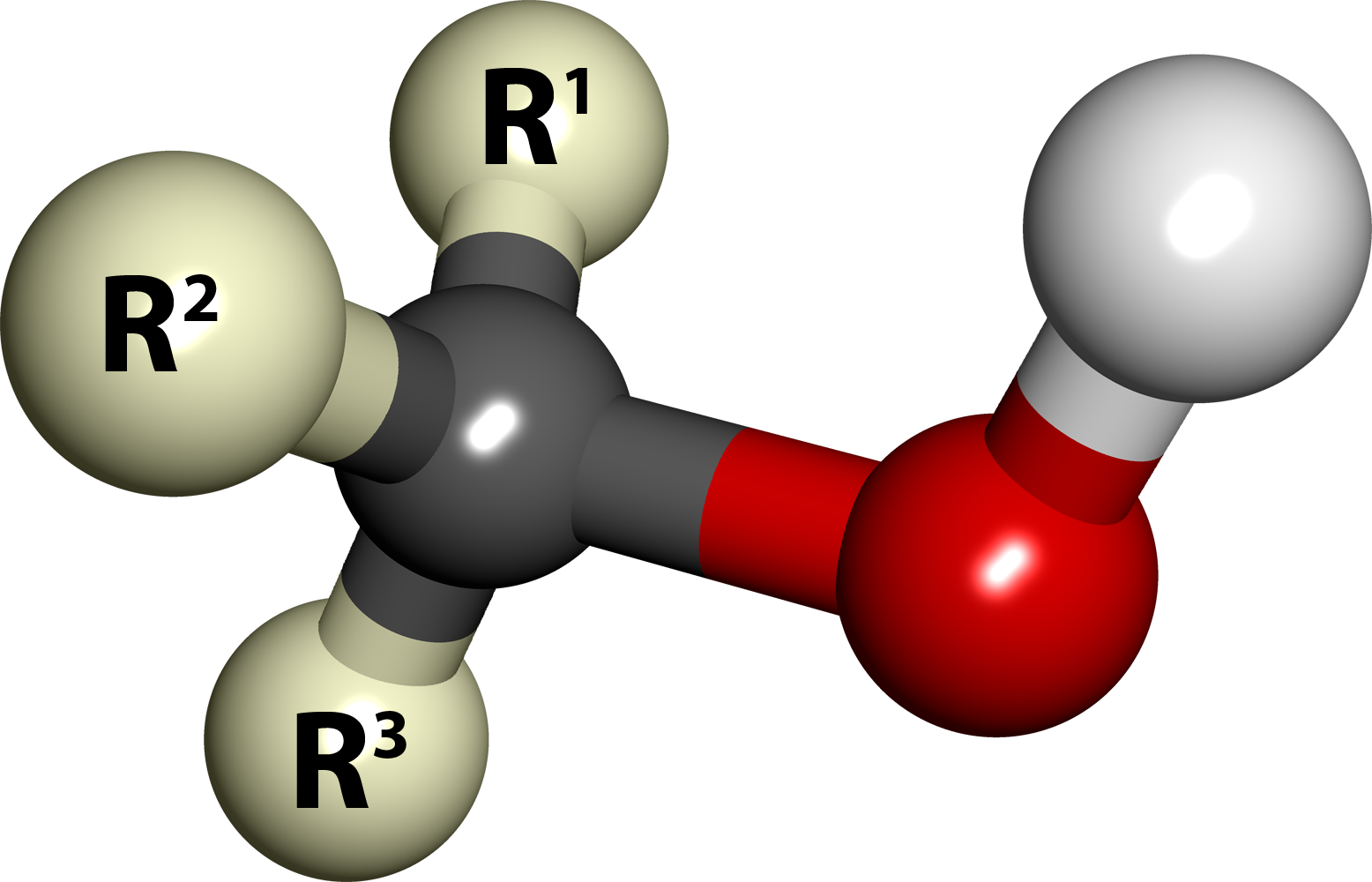
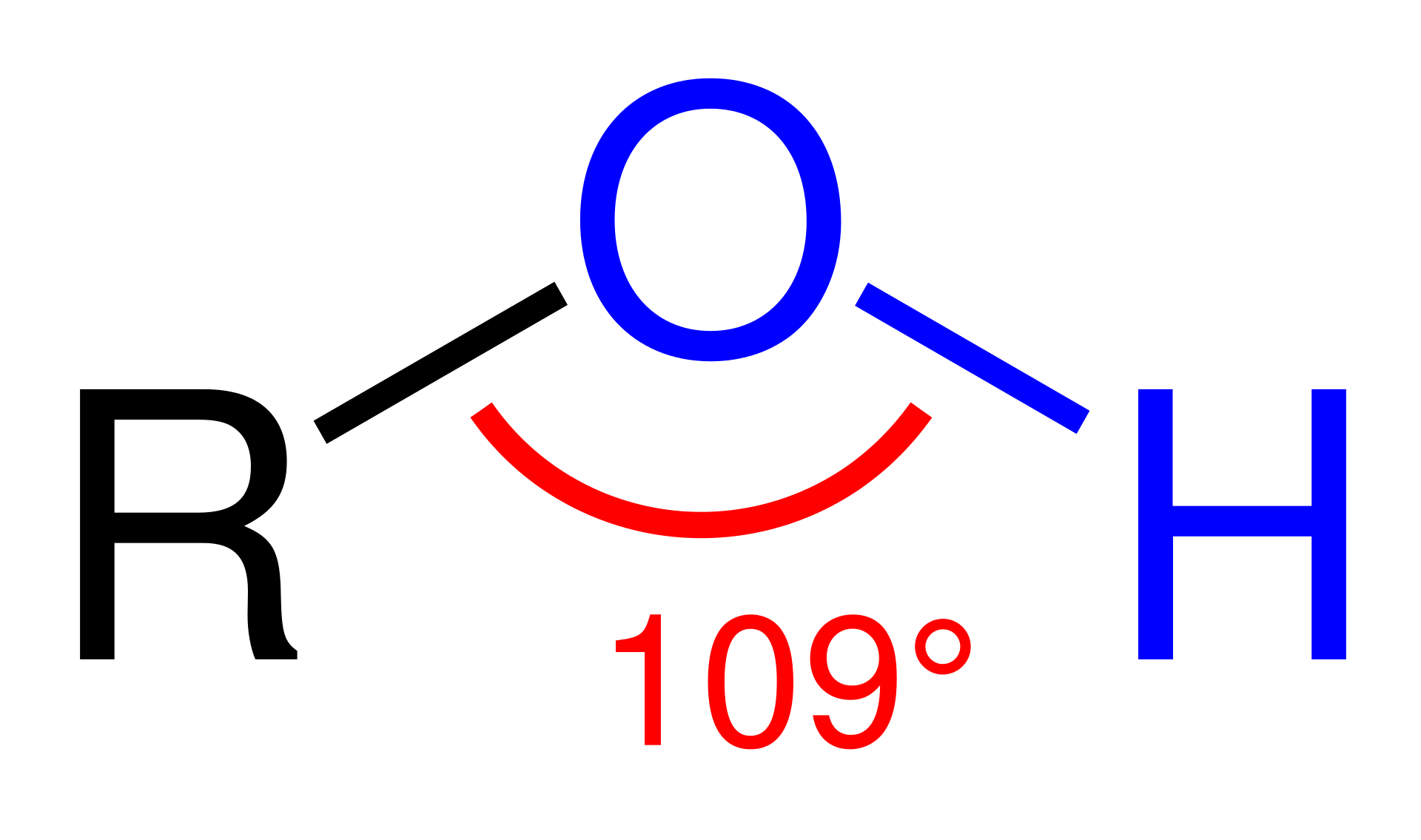

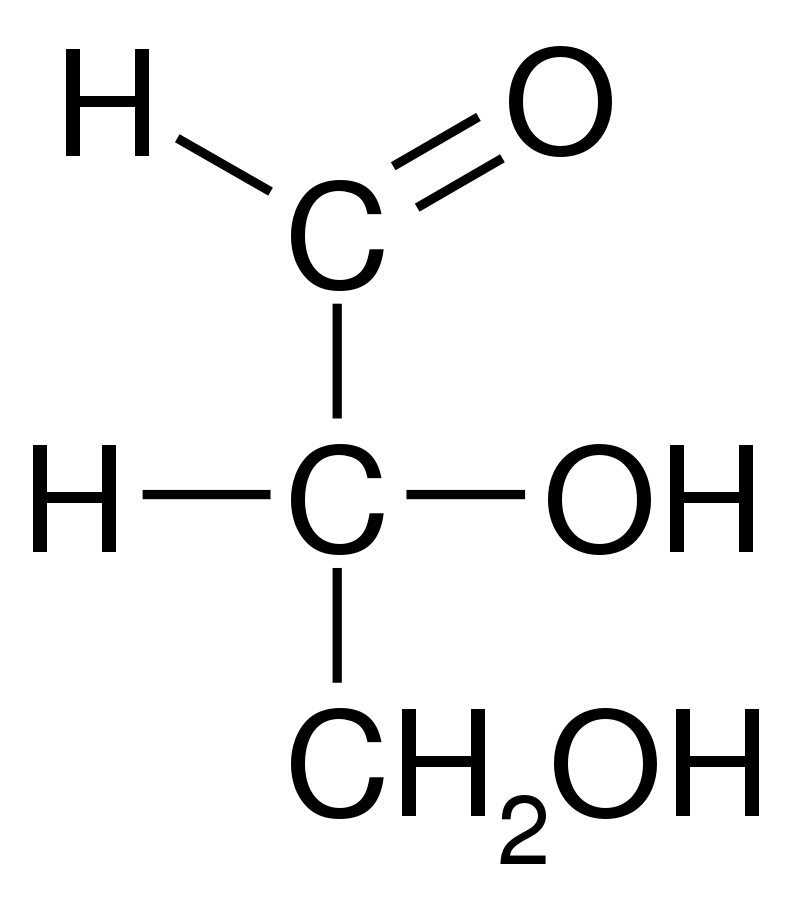
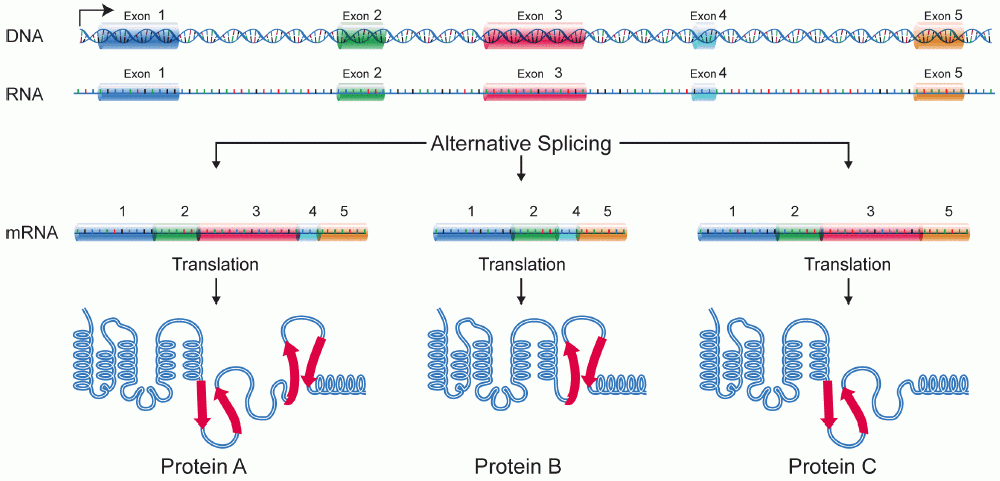
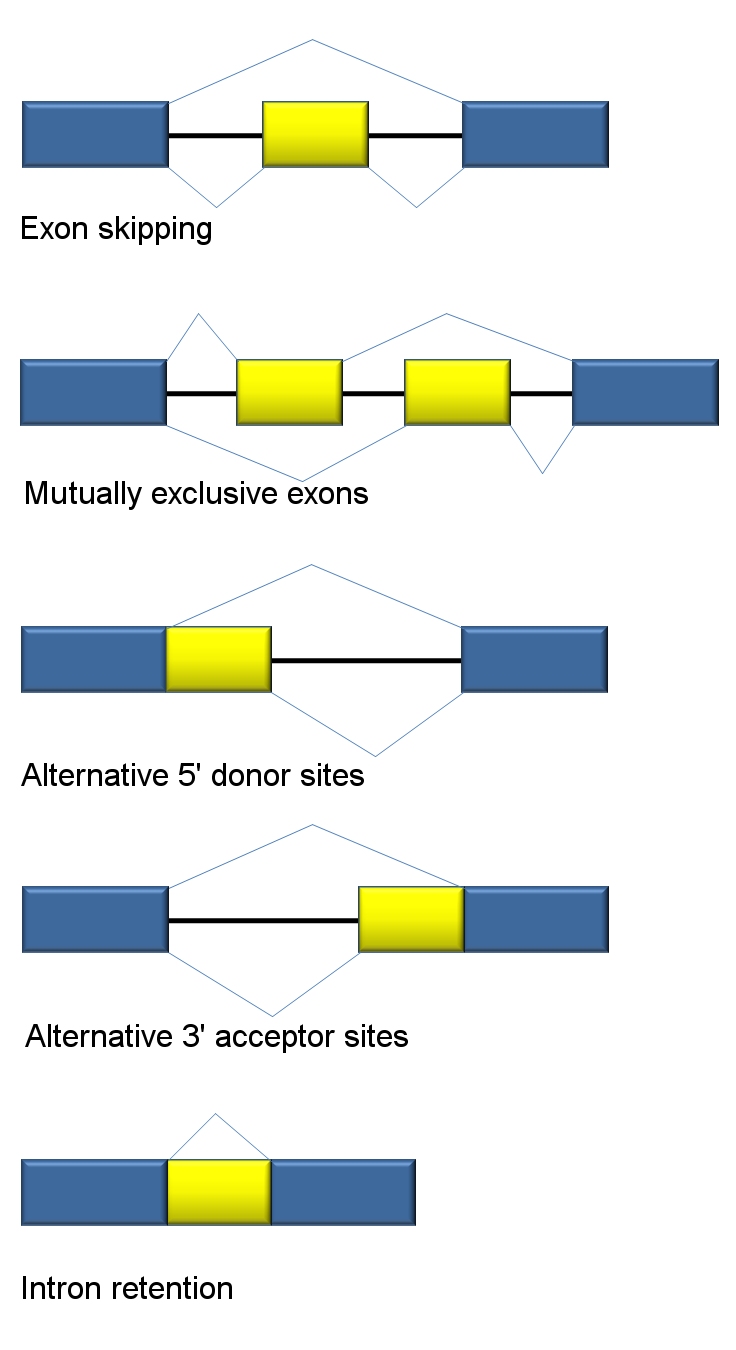
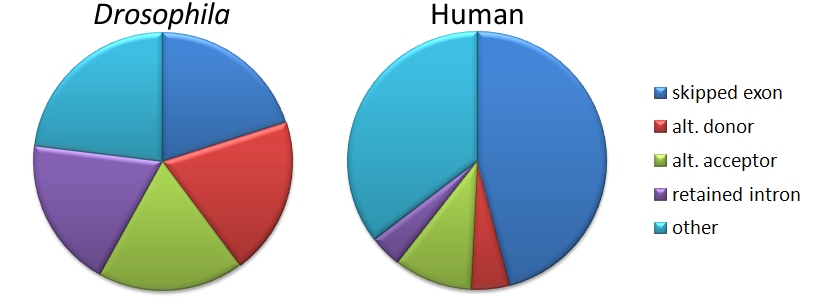
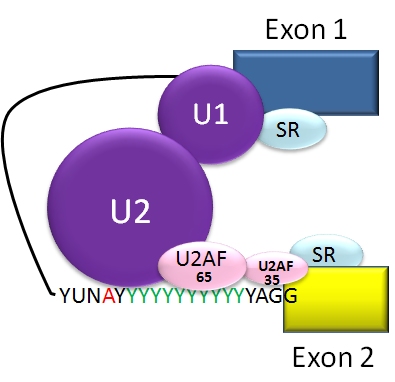
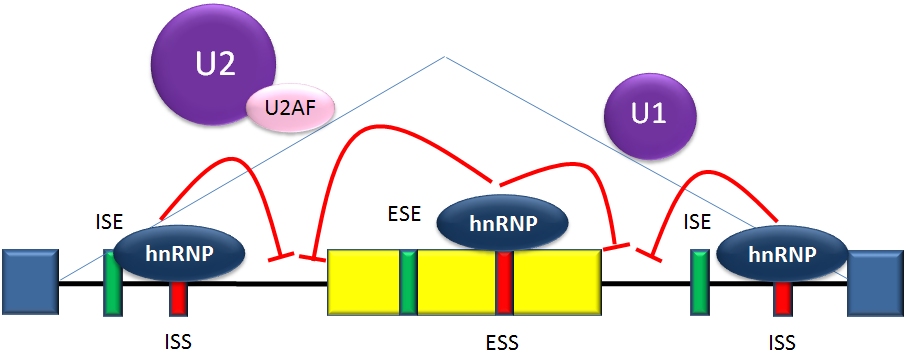
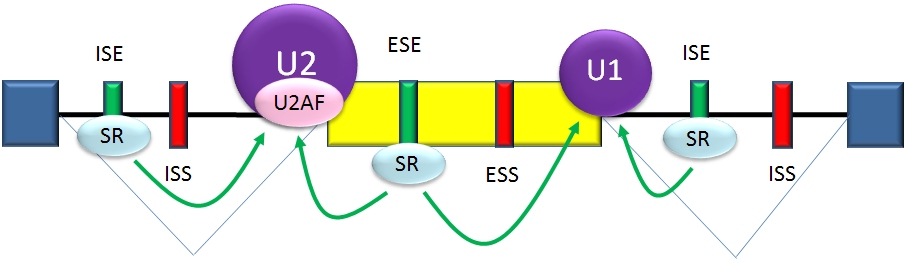
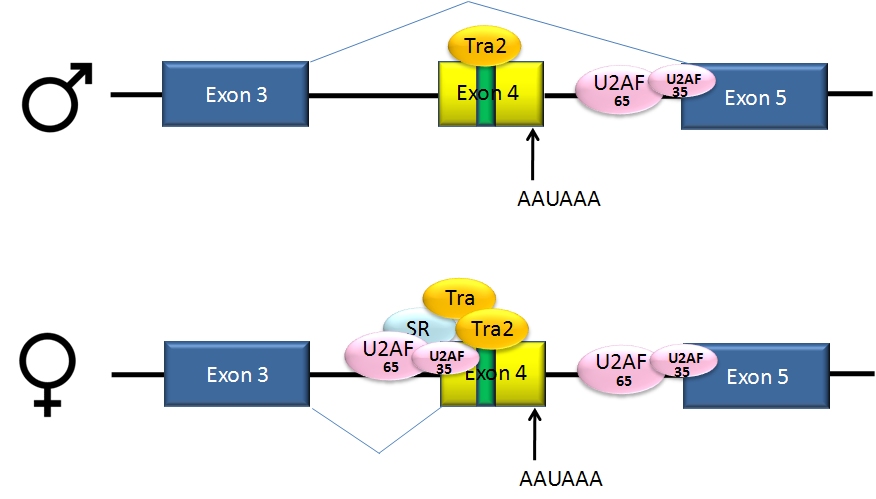
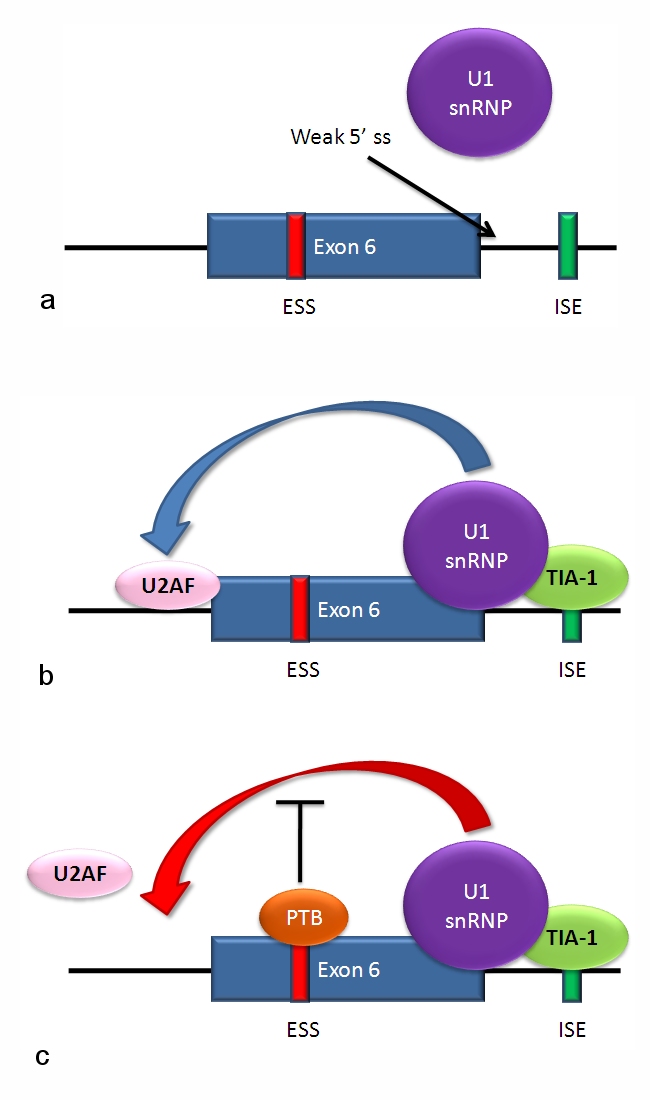
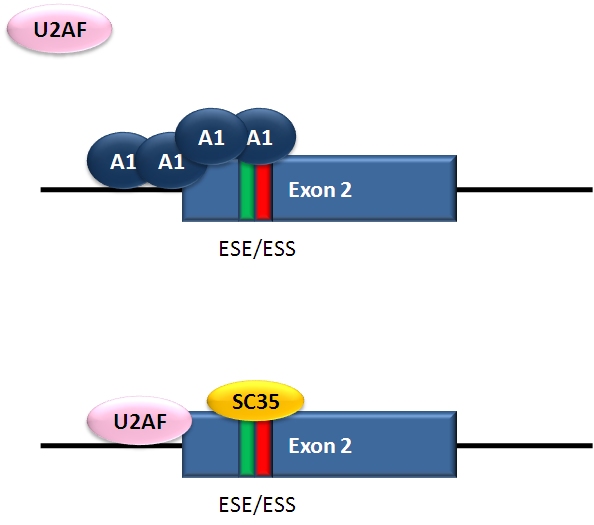
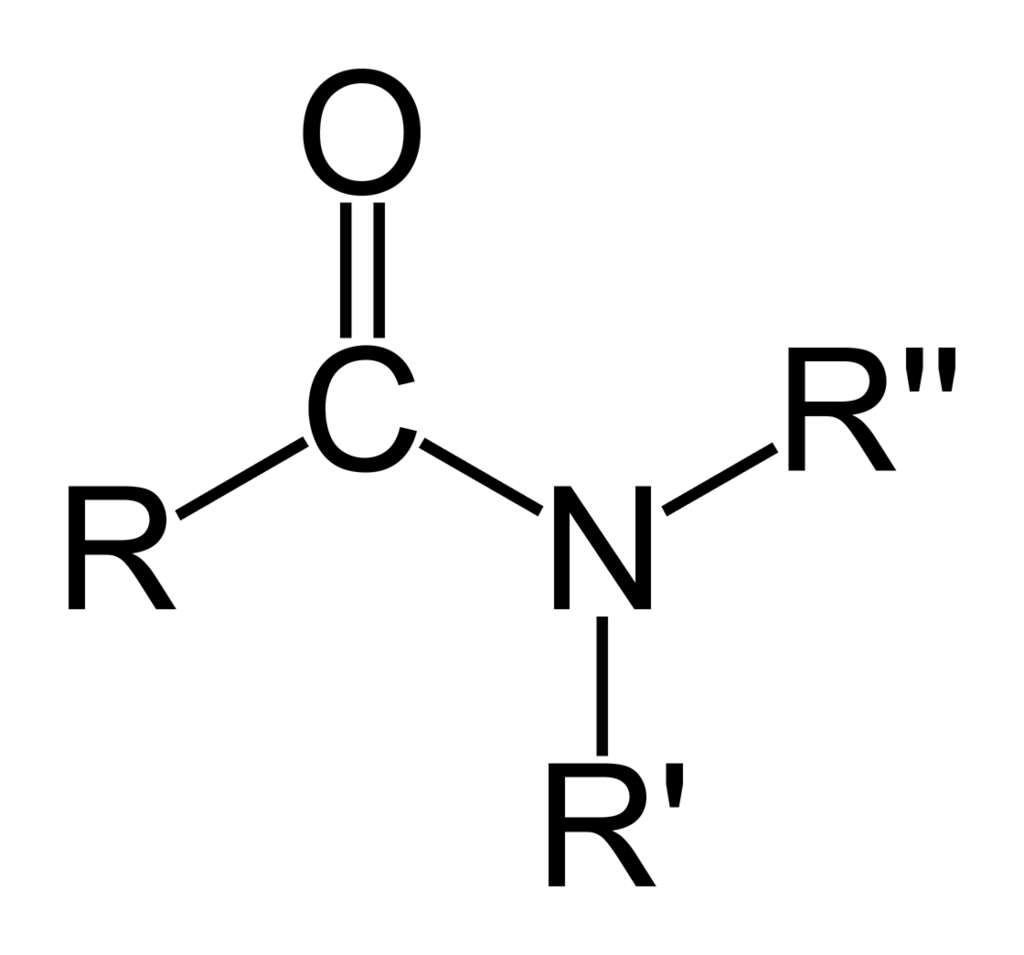
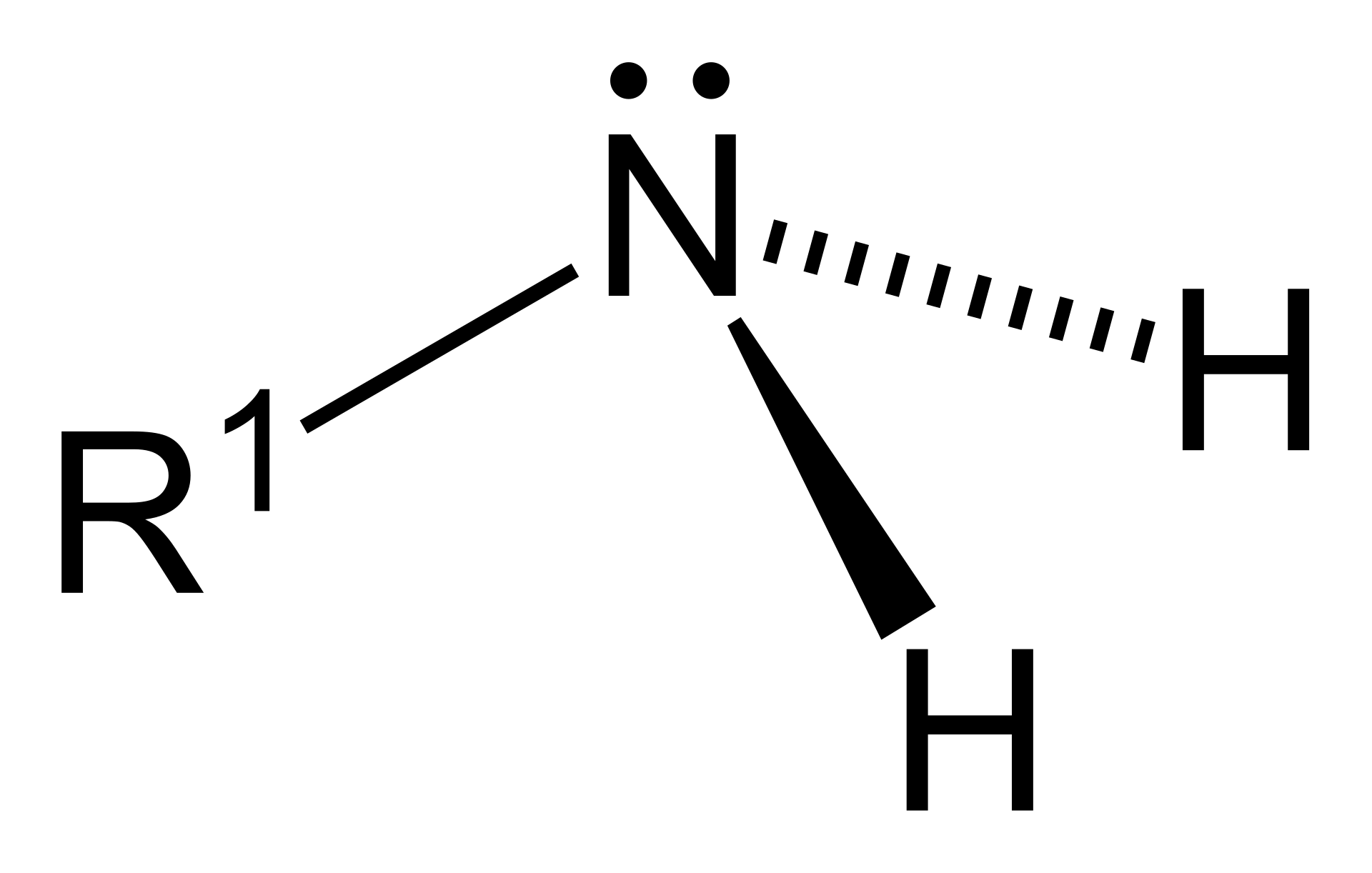
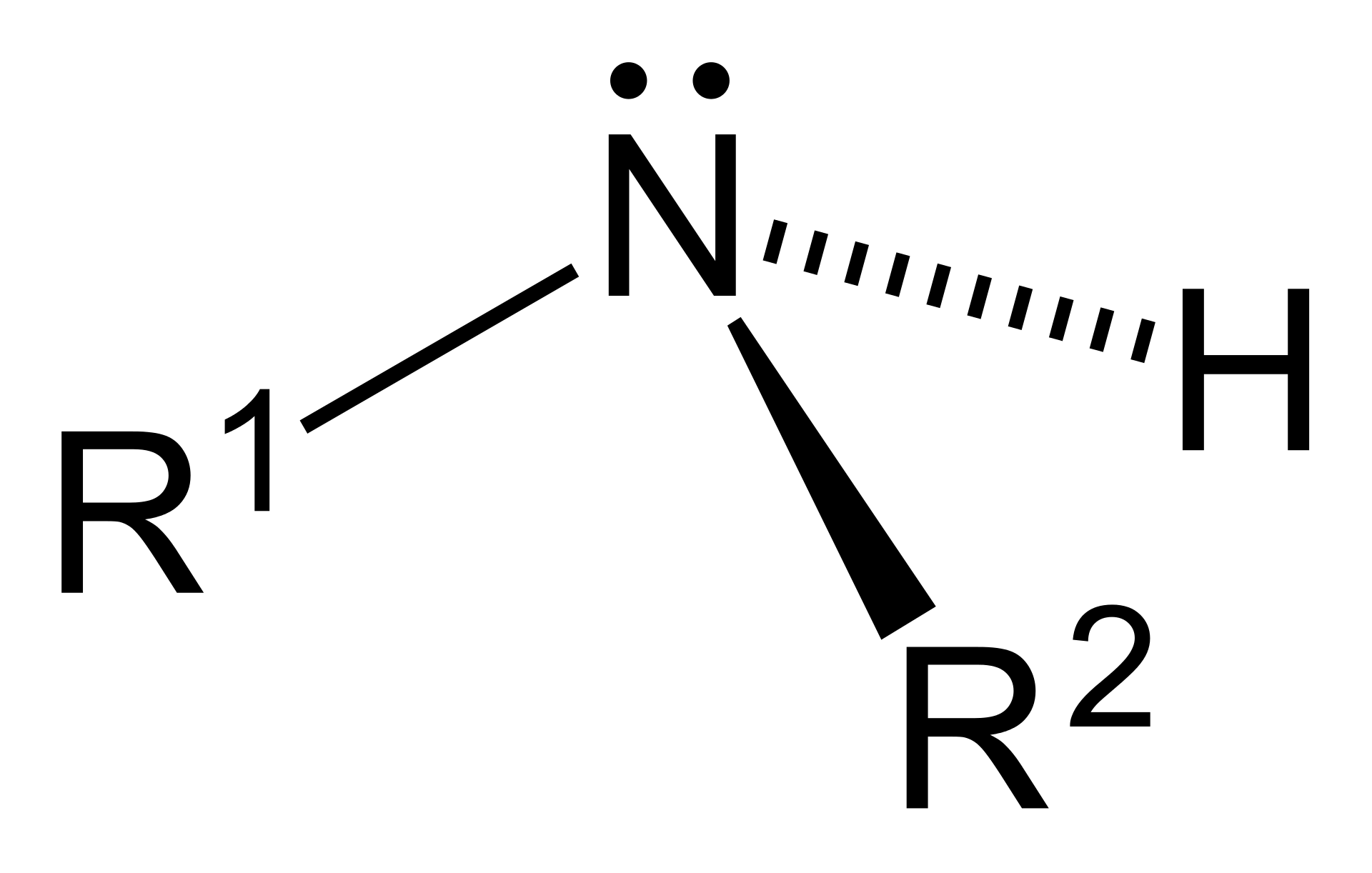
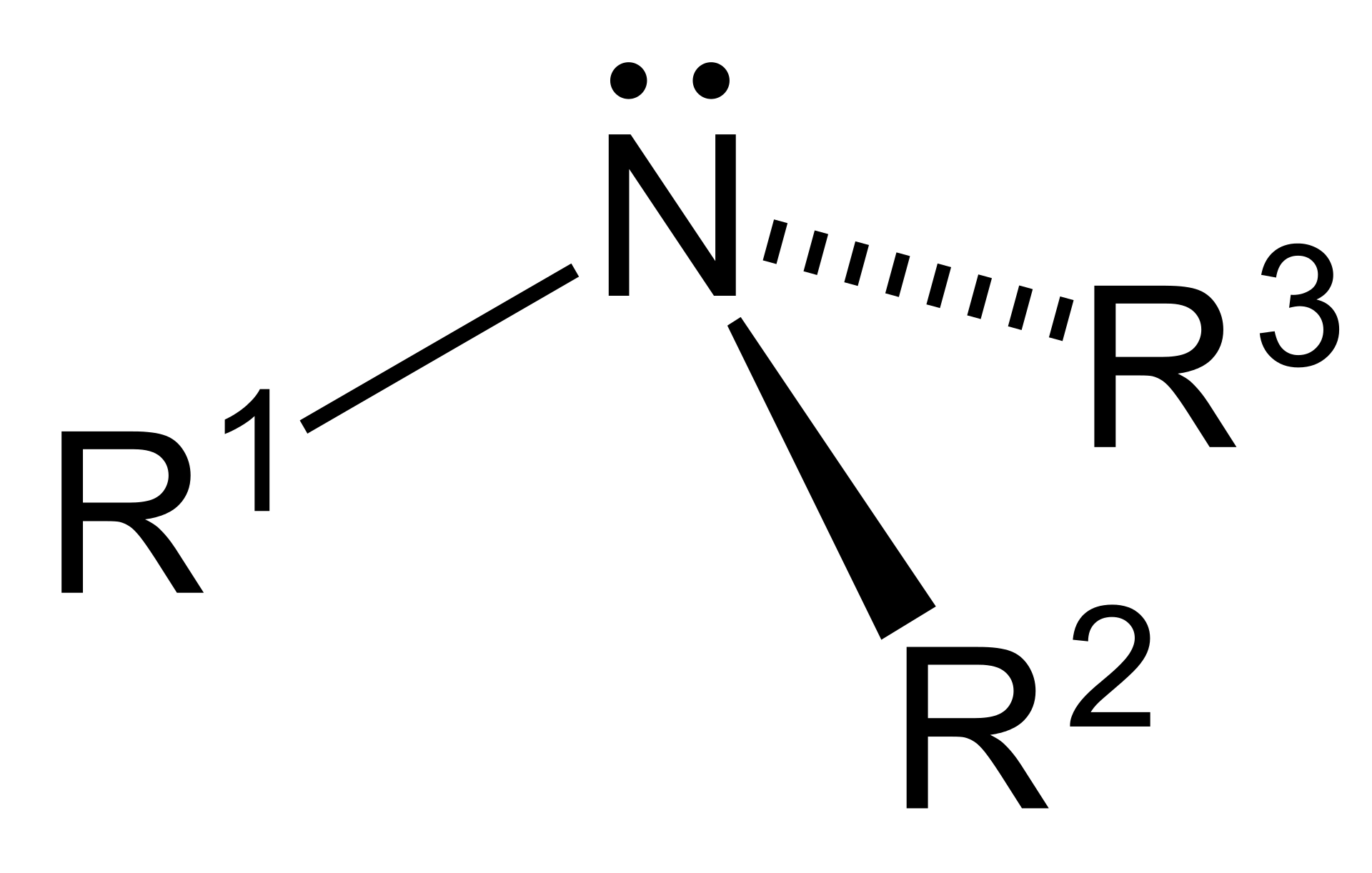
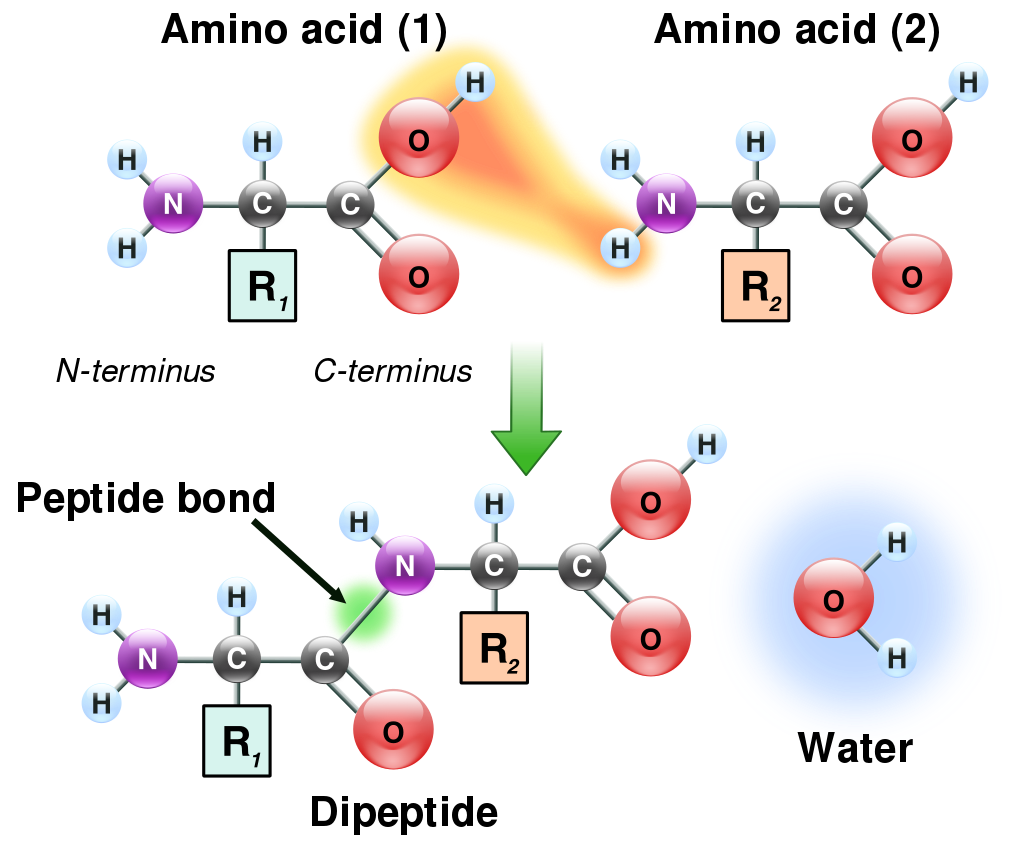
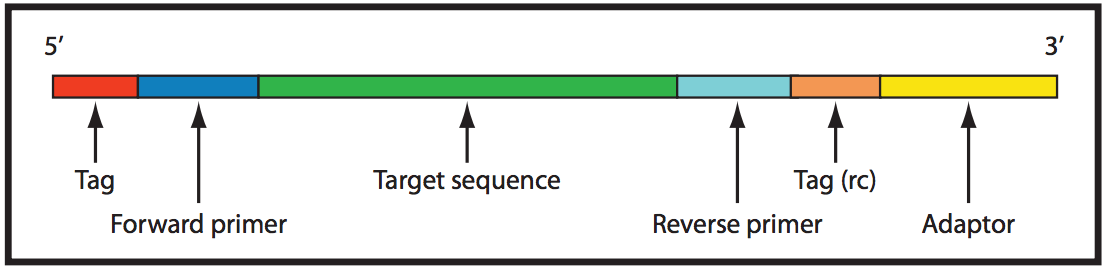

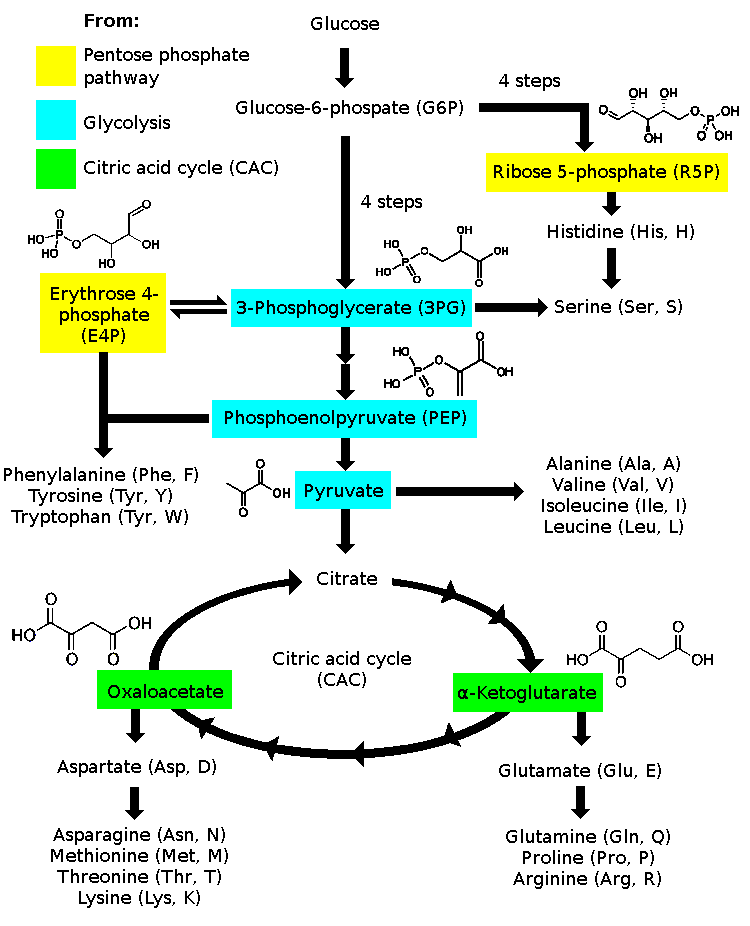
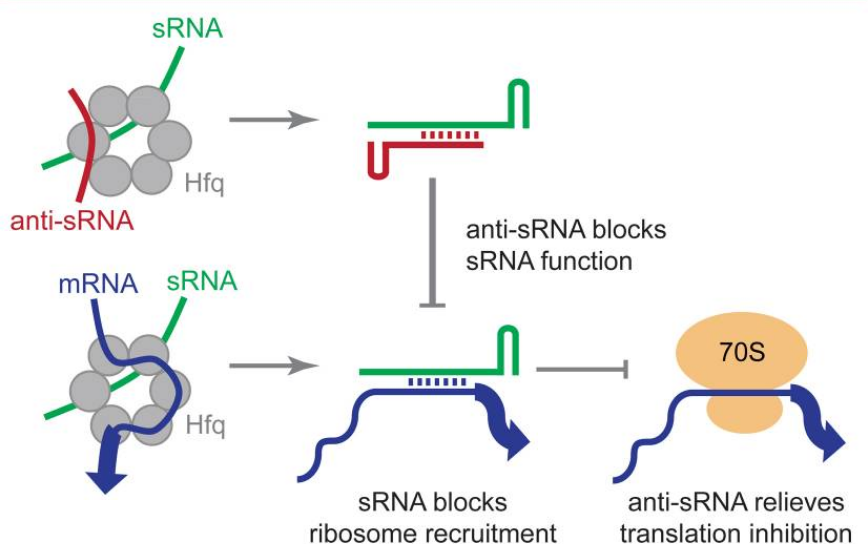
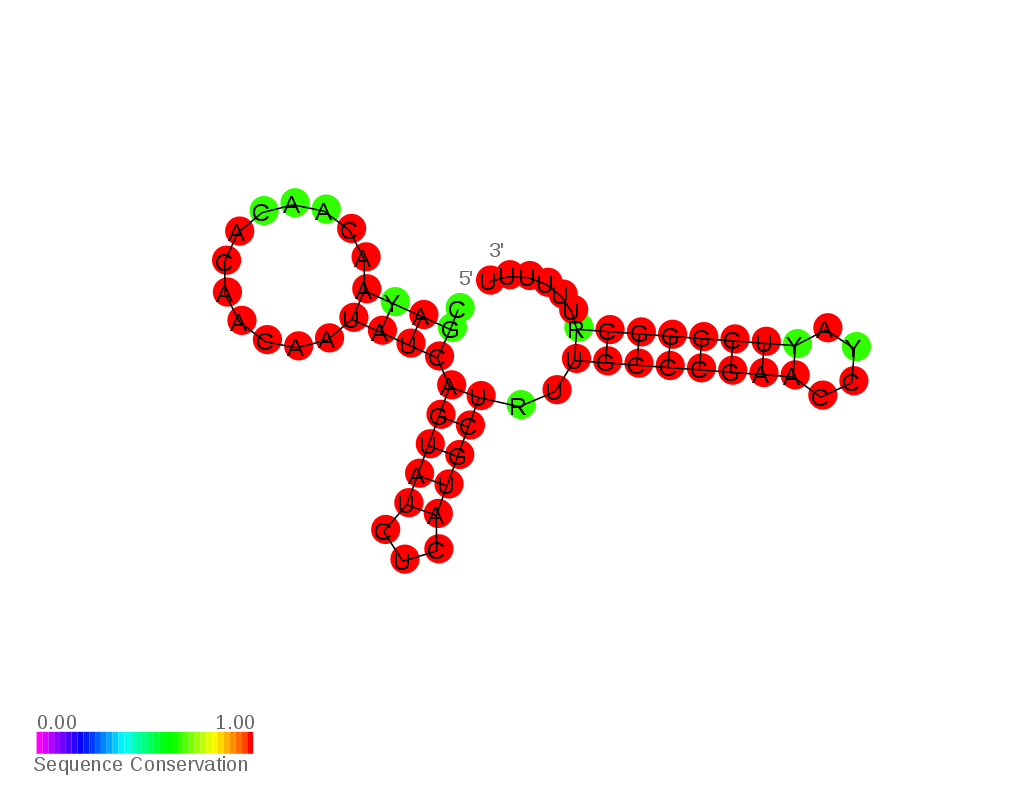

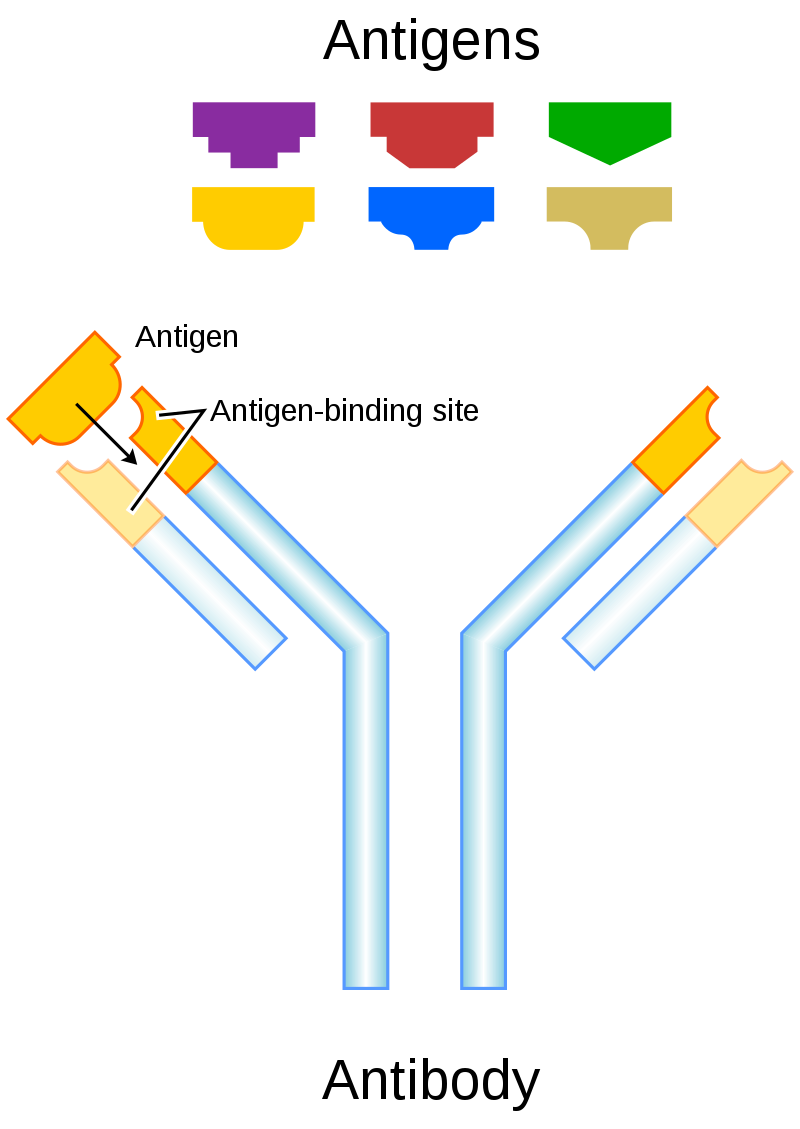
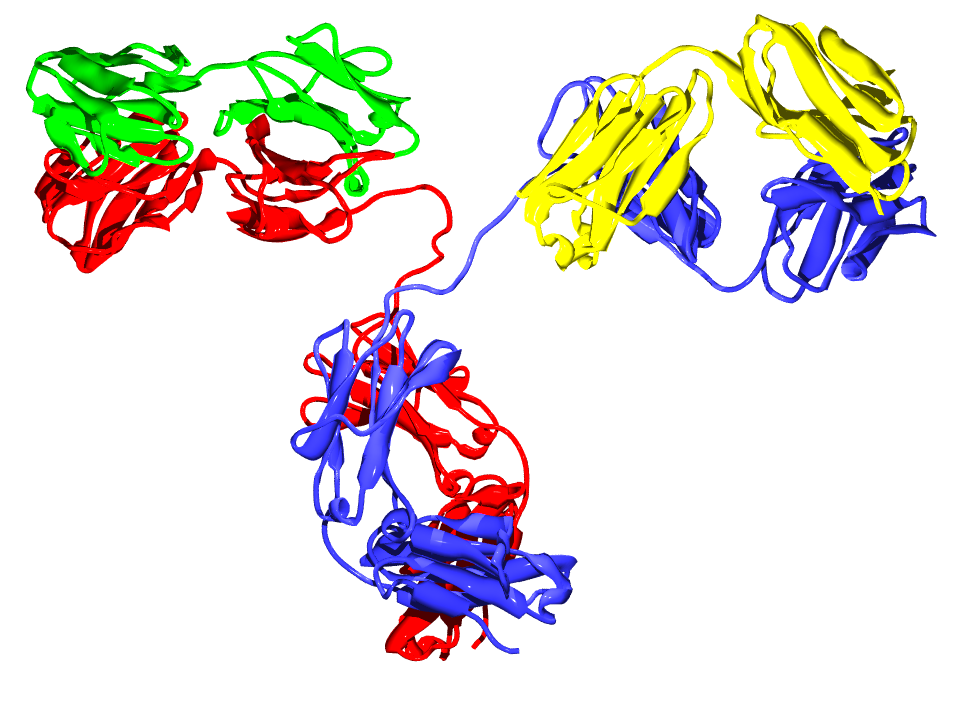
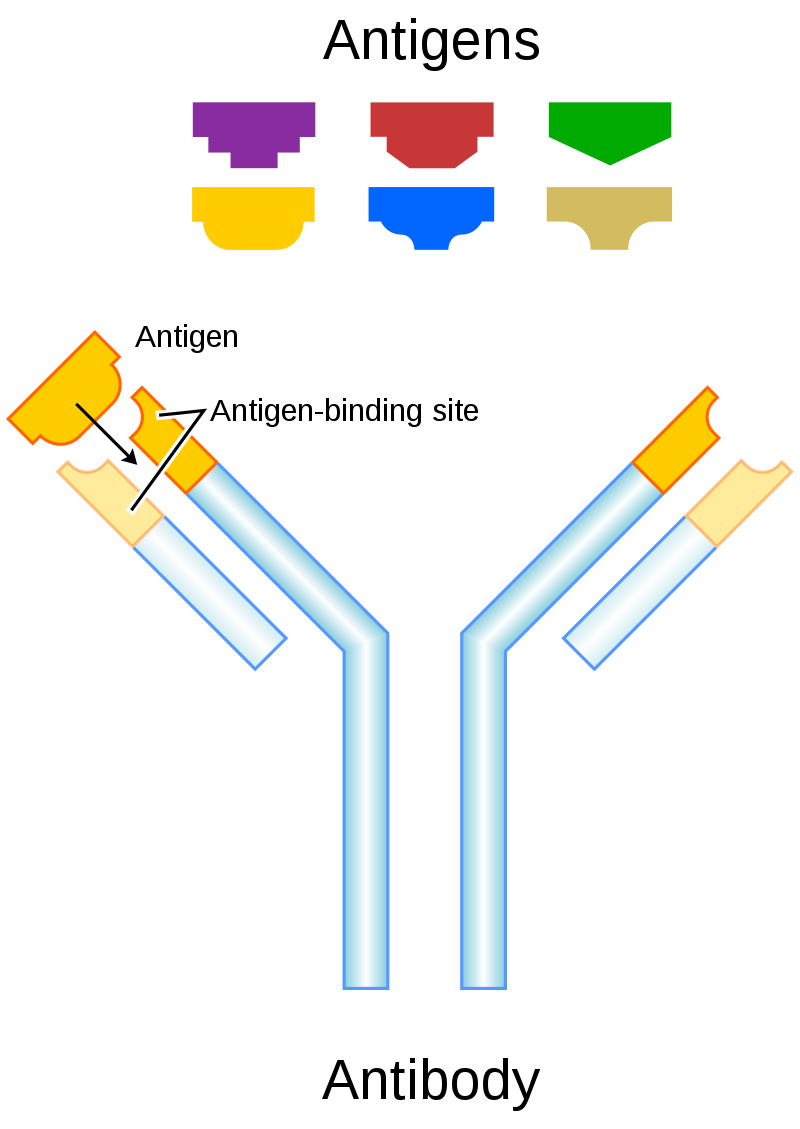
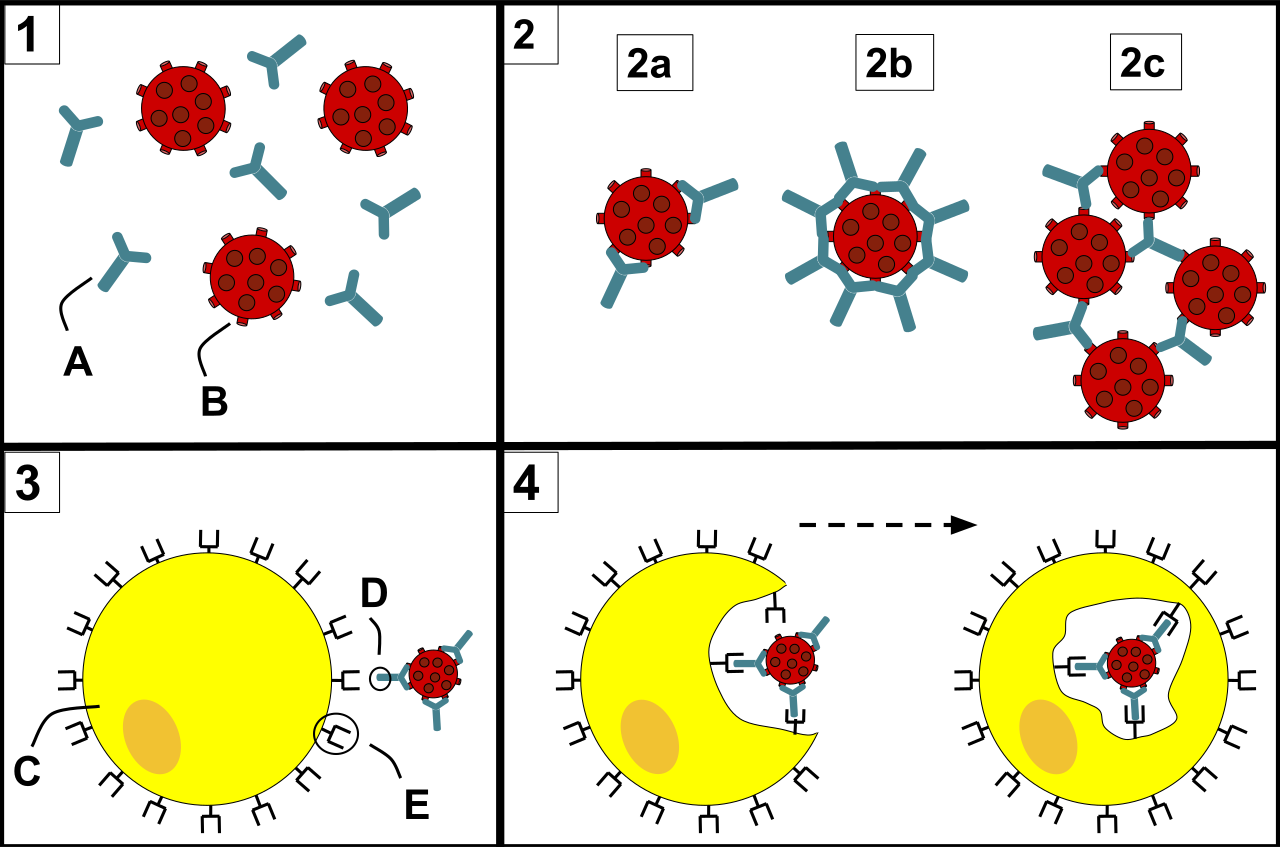
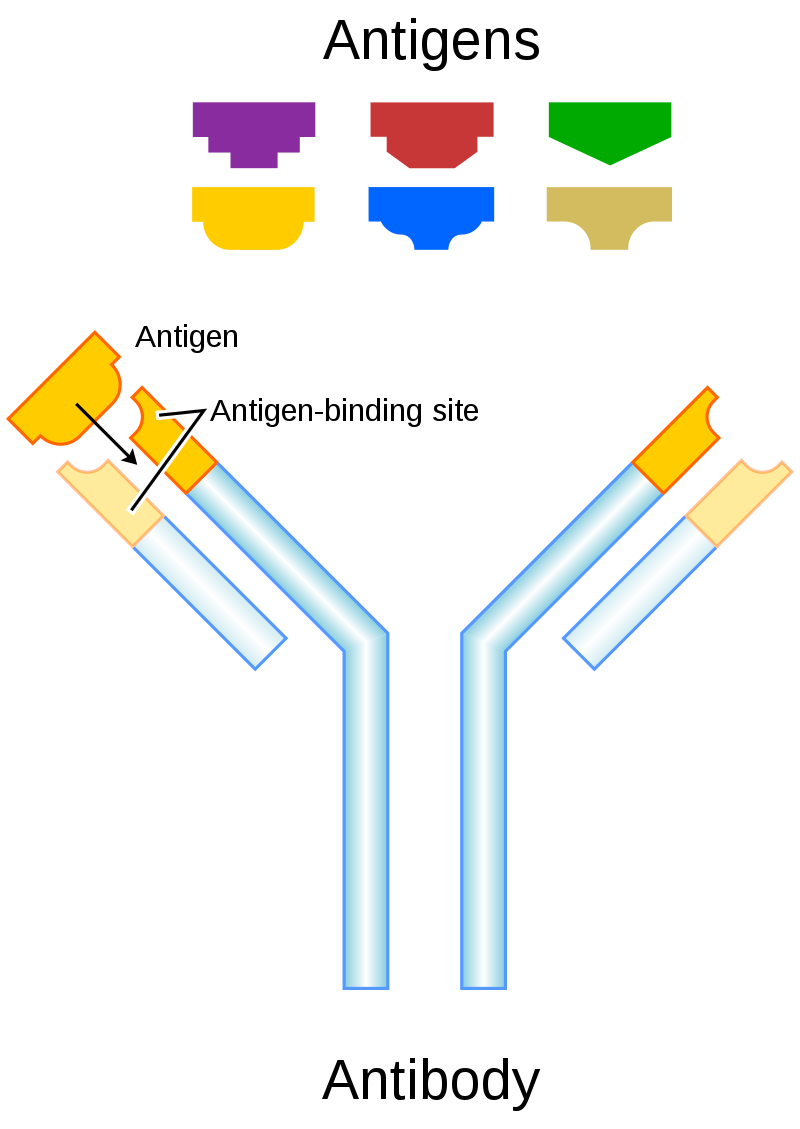
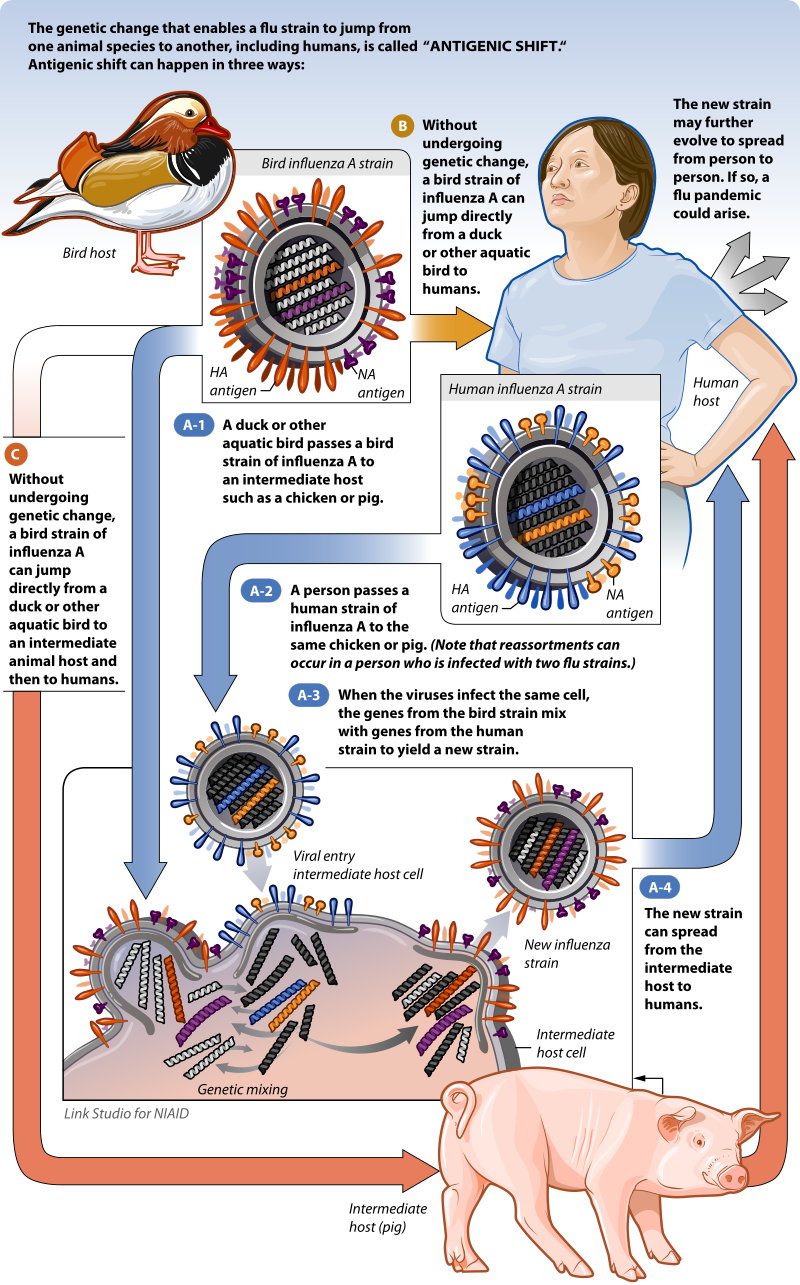
_structure.png)
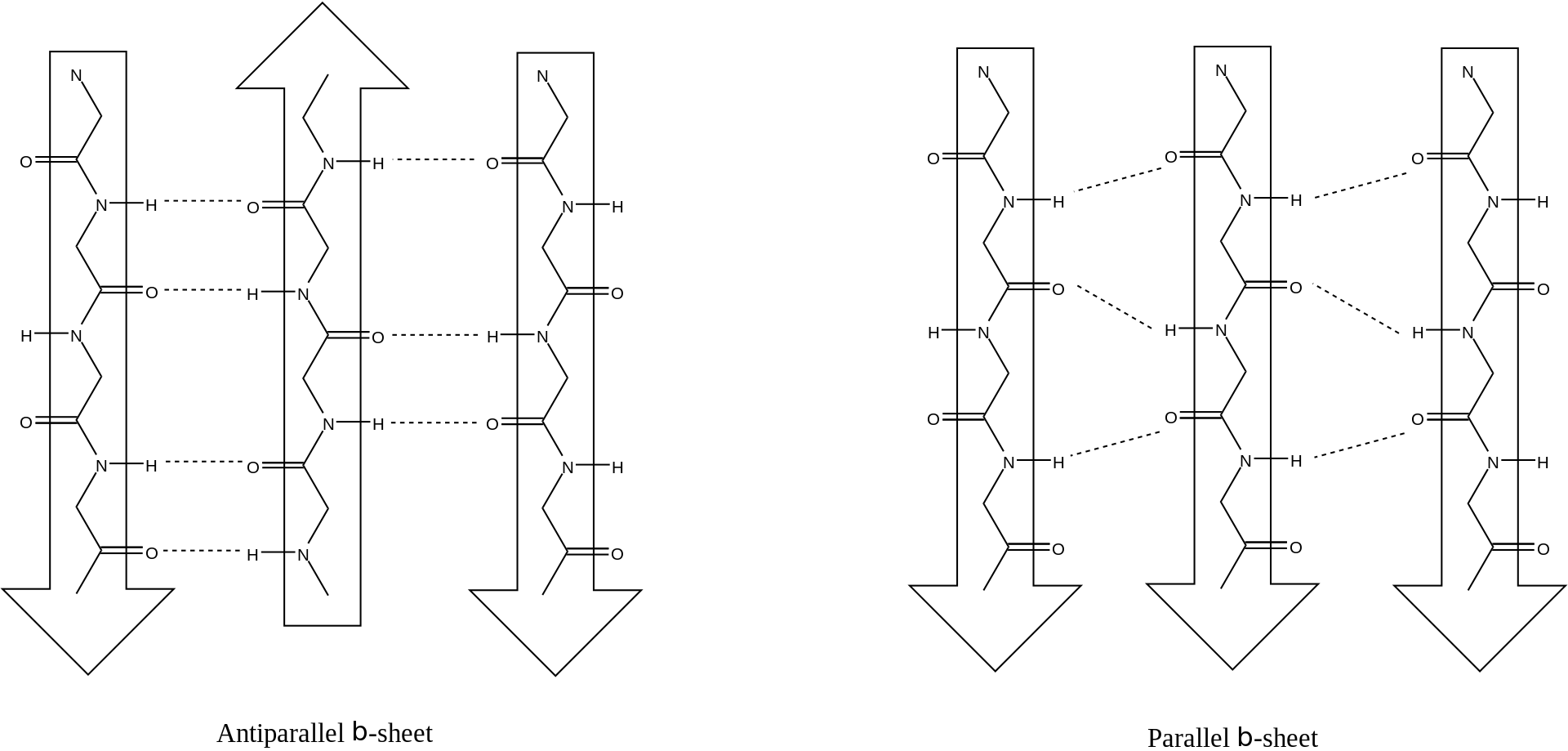
_.png)
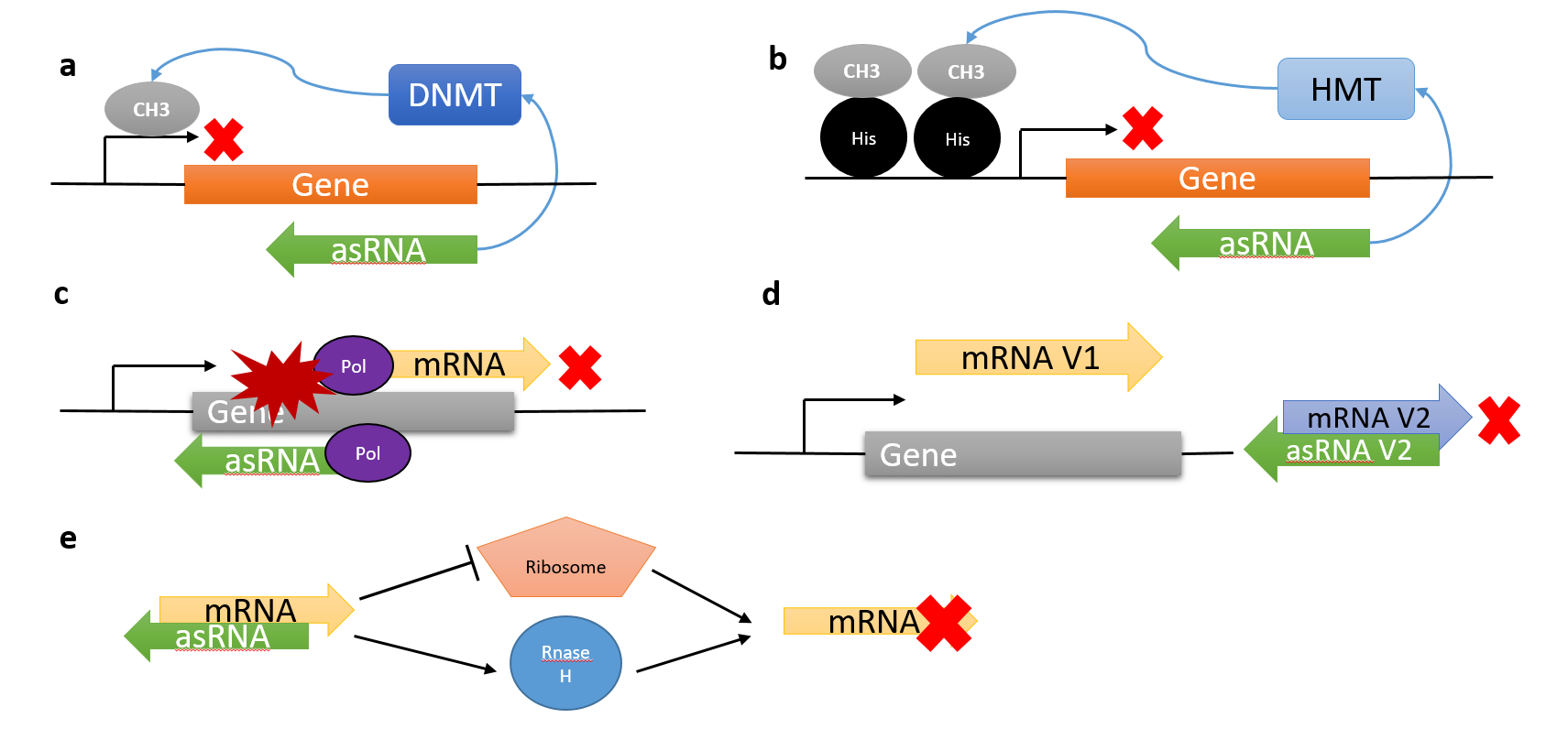
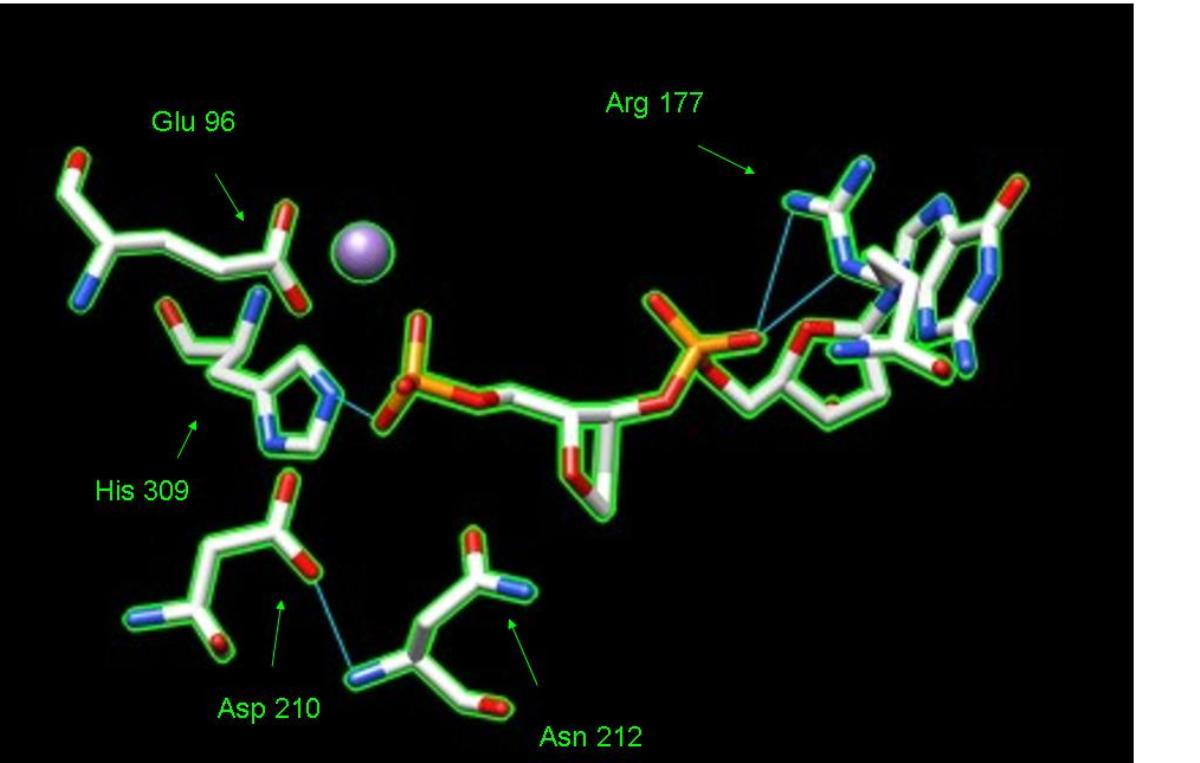
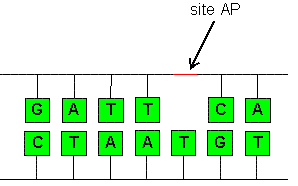

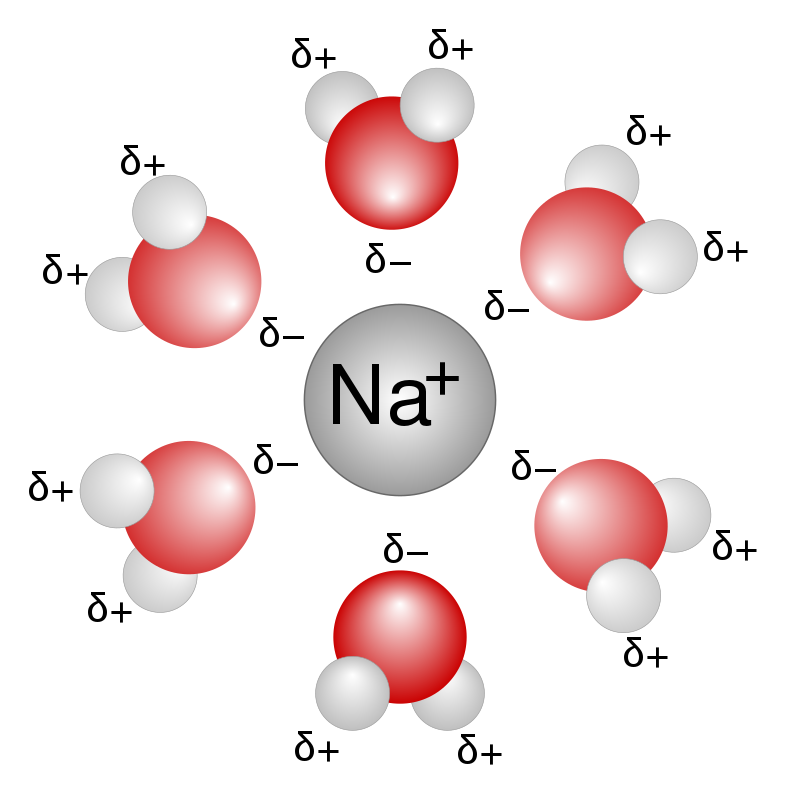
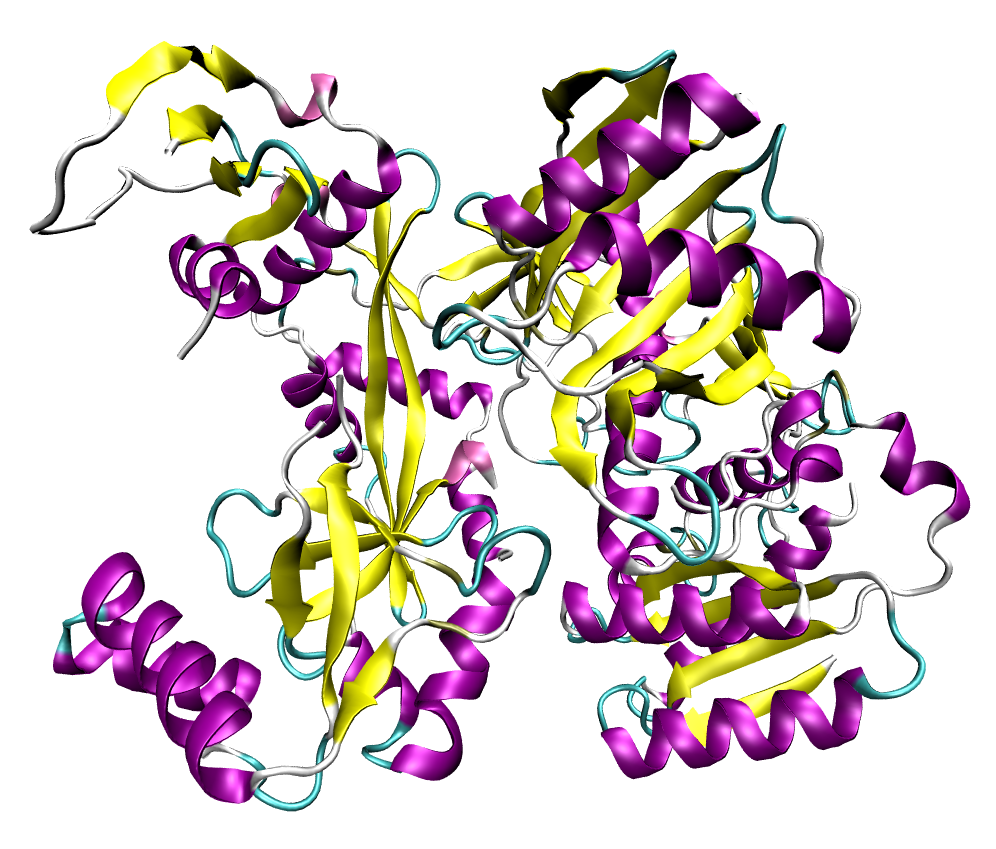
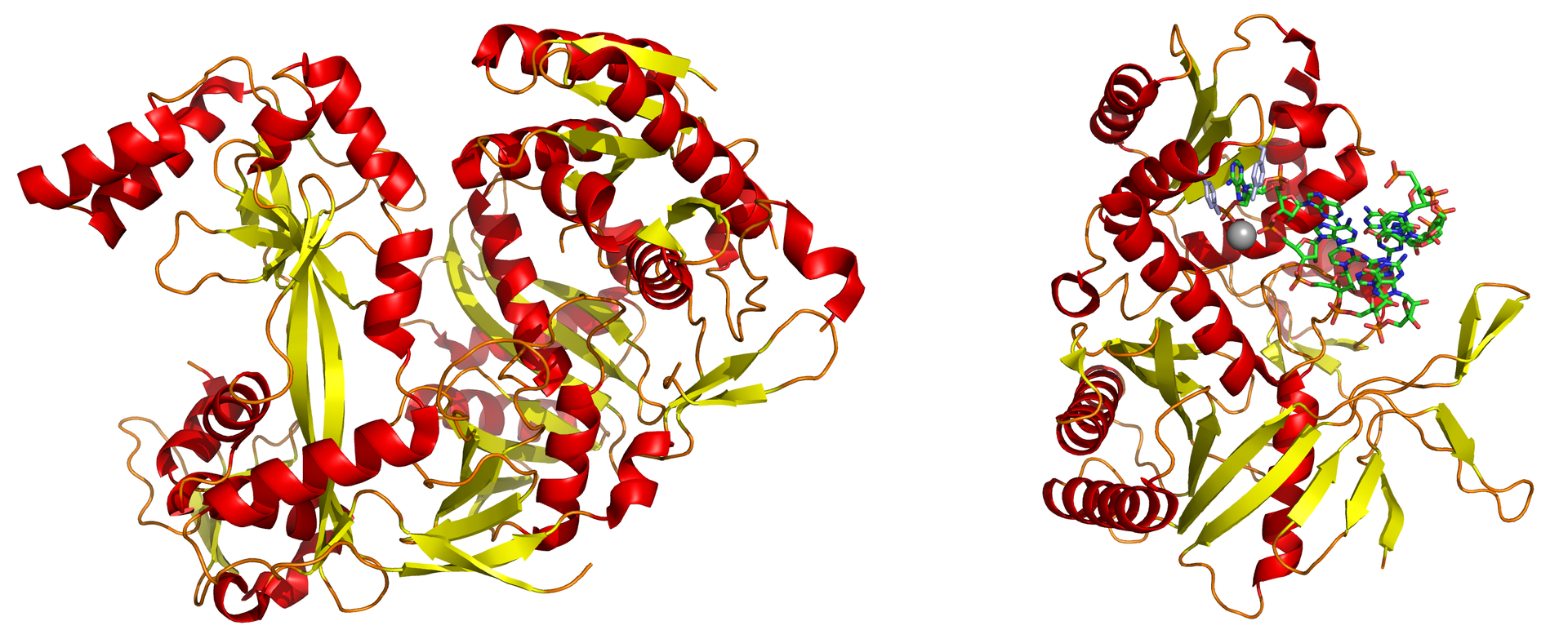
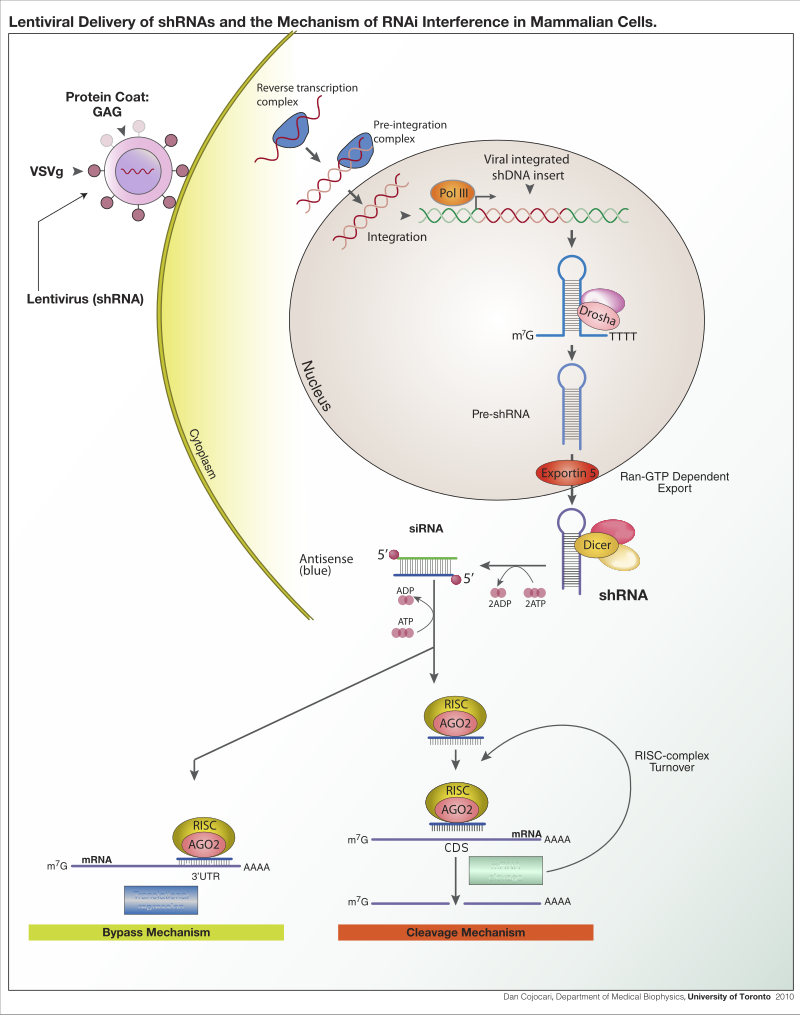

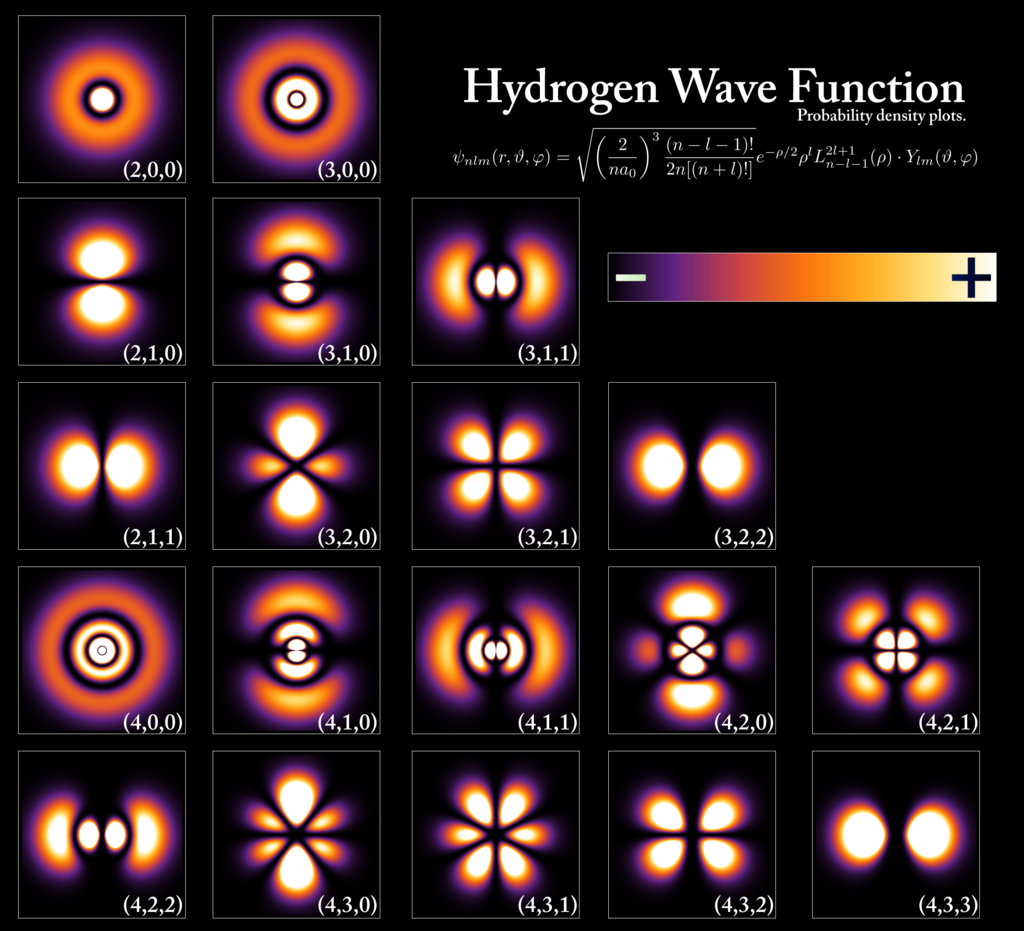
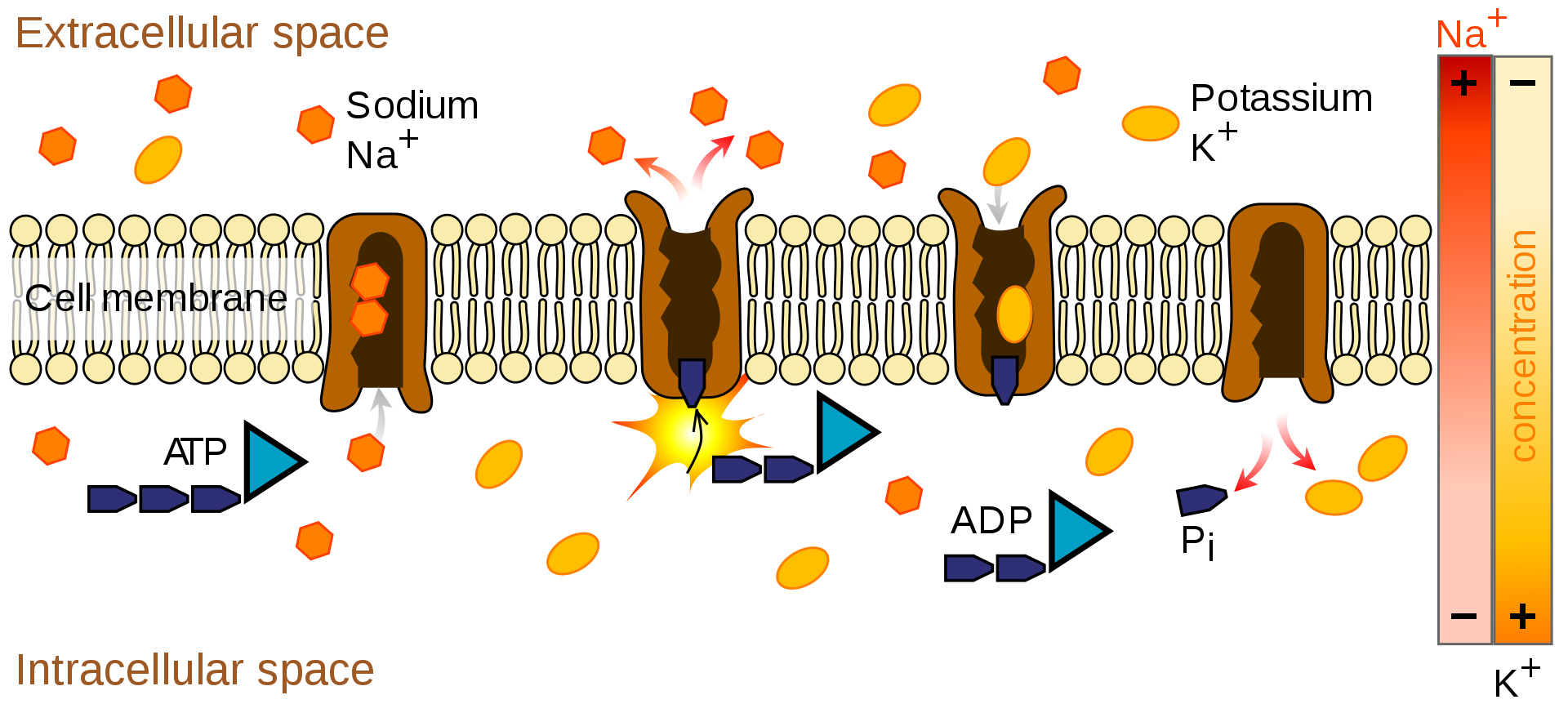
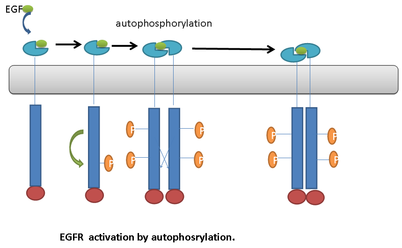
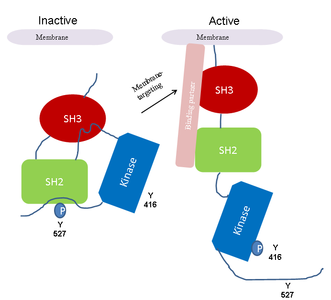
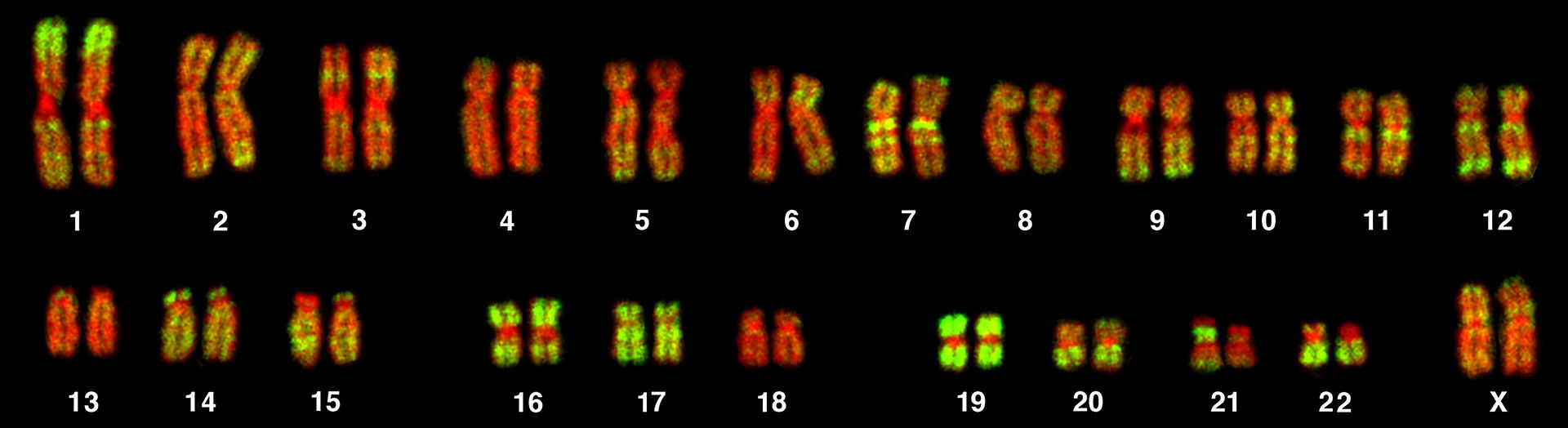
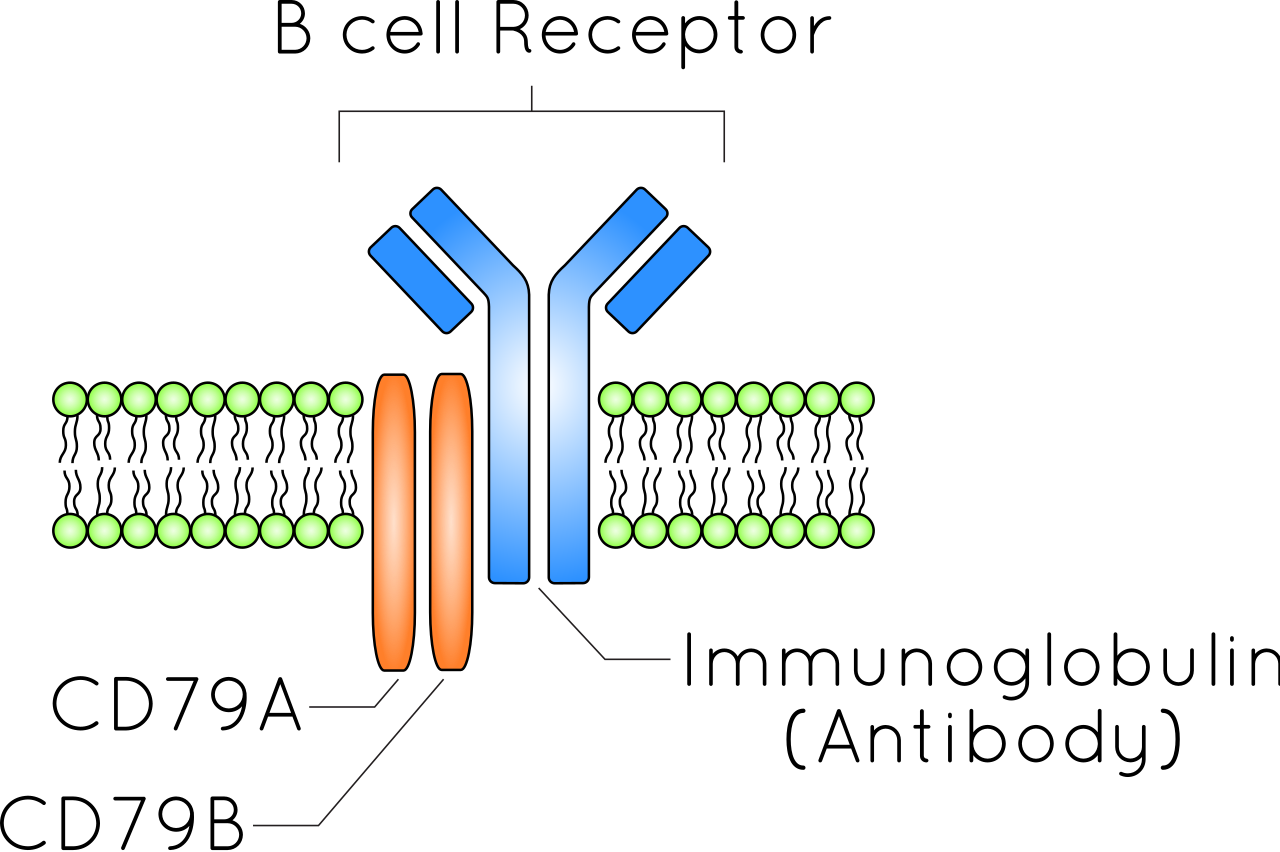
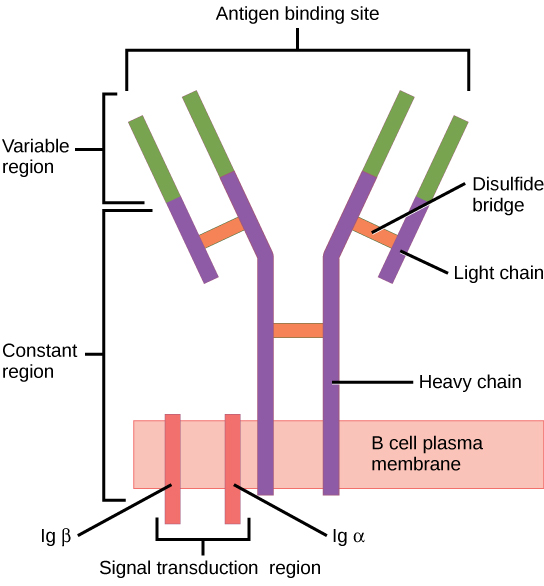
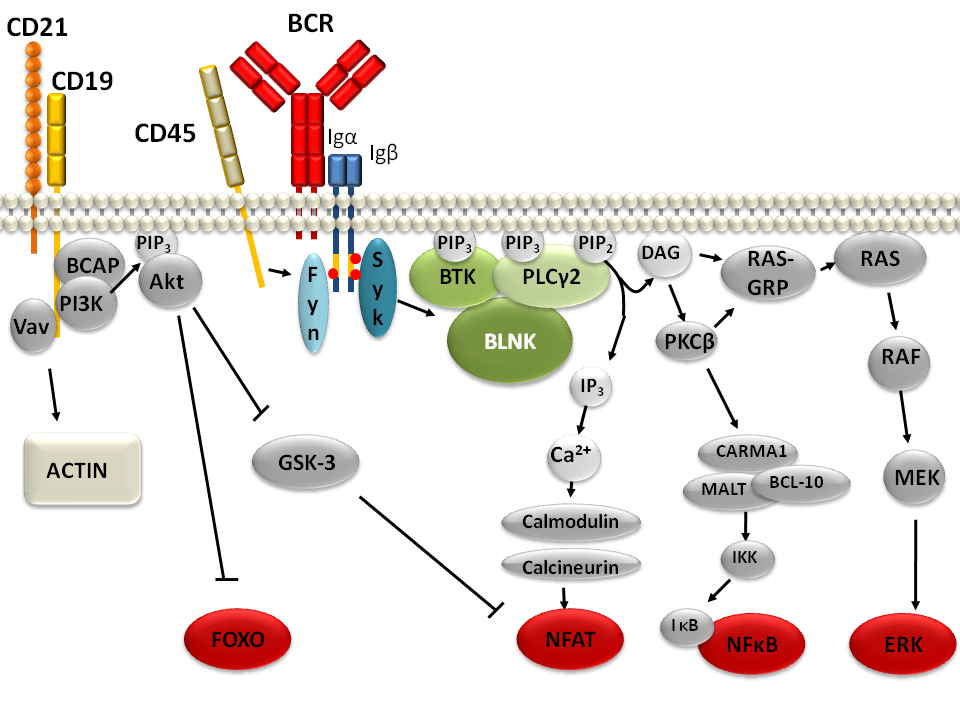
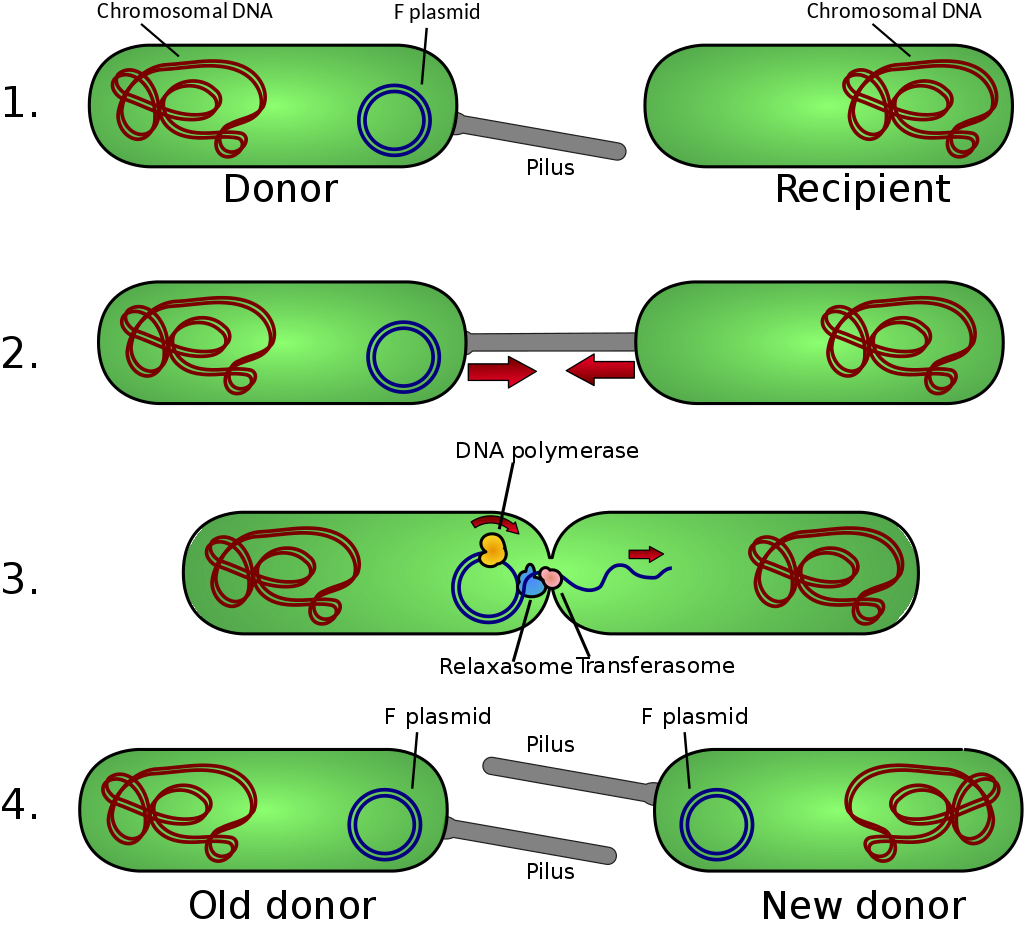
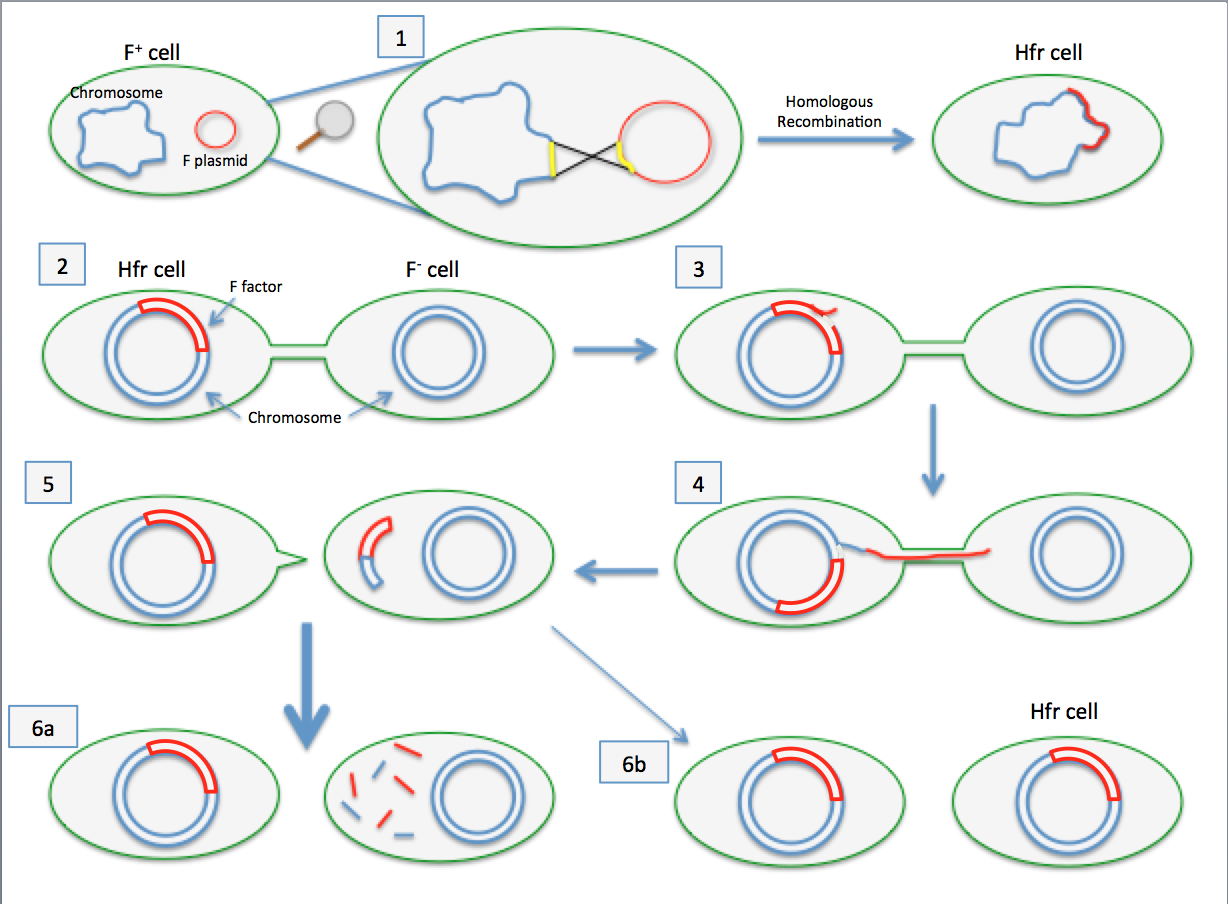
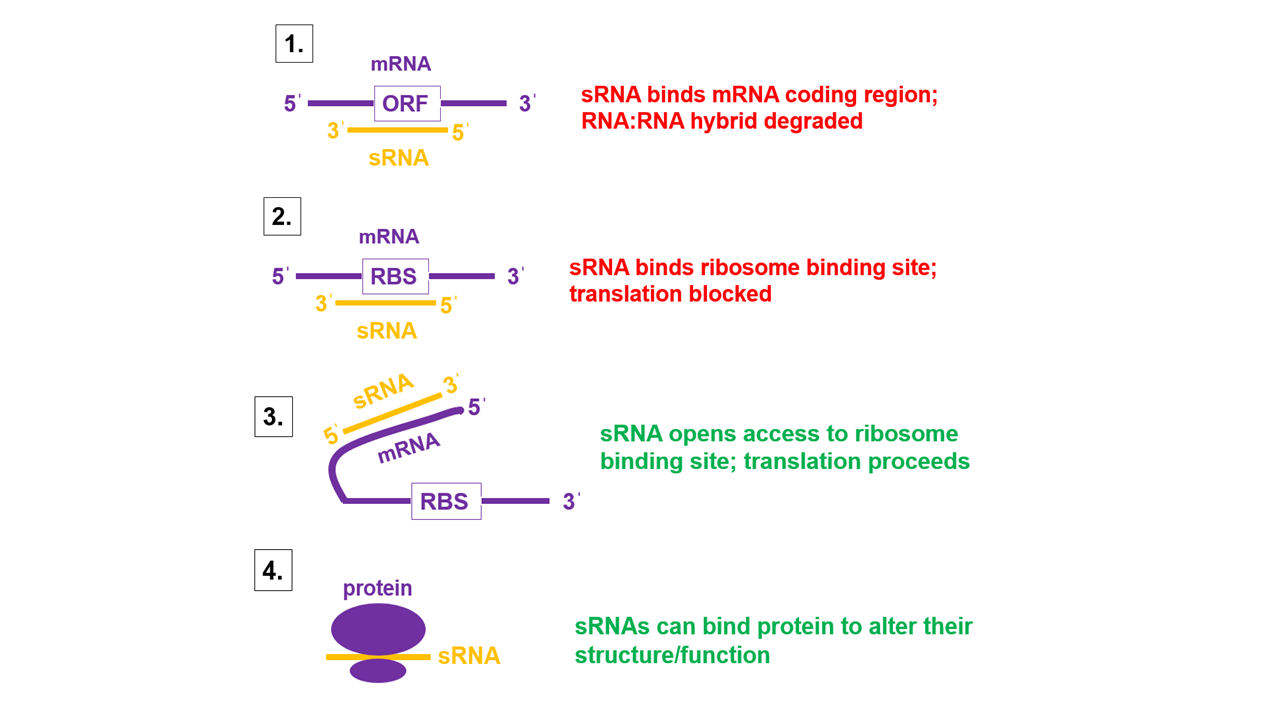

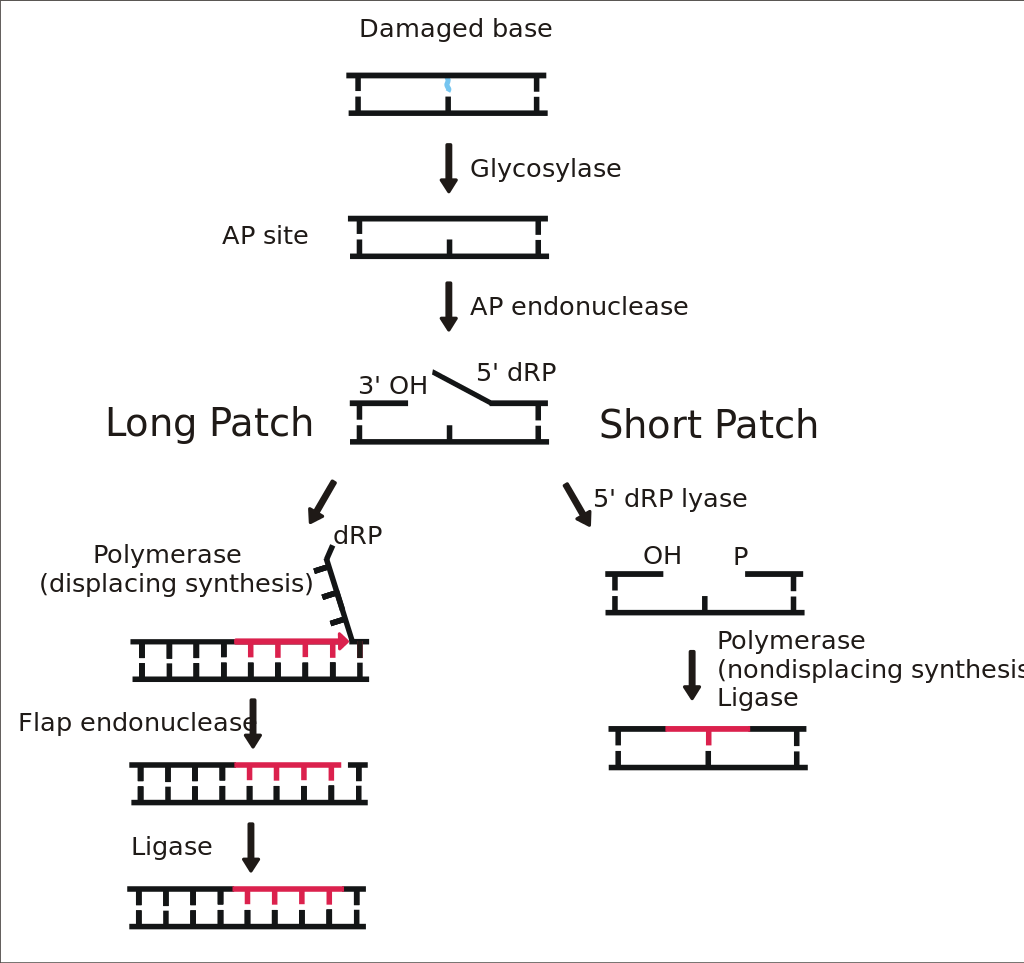
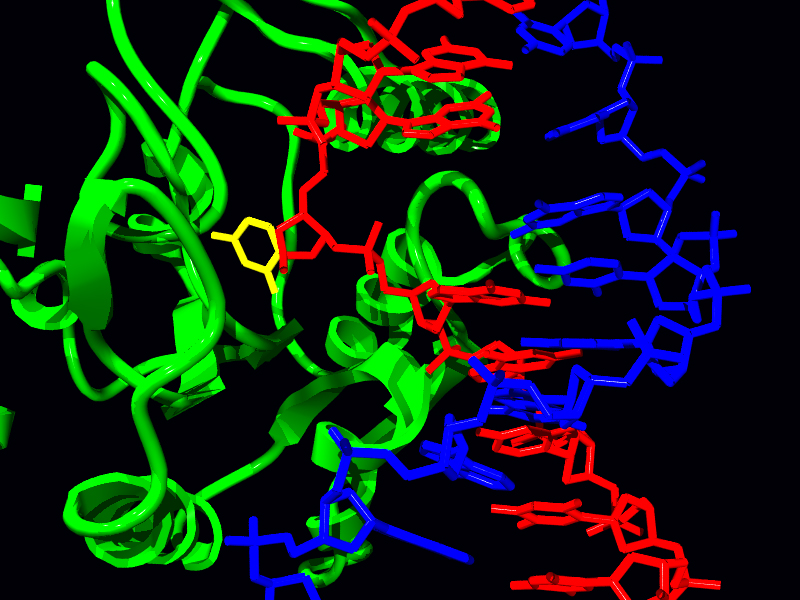
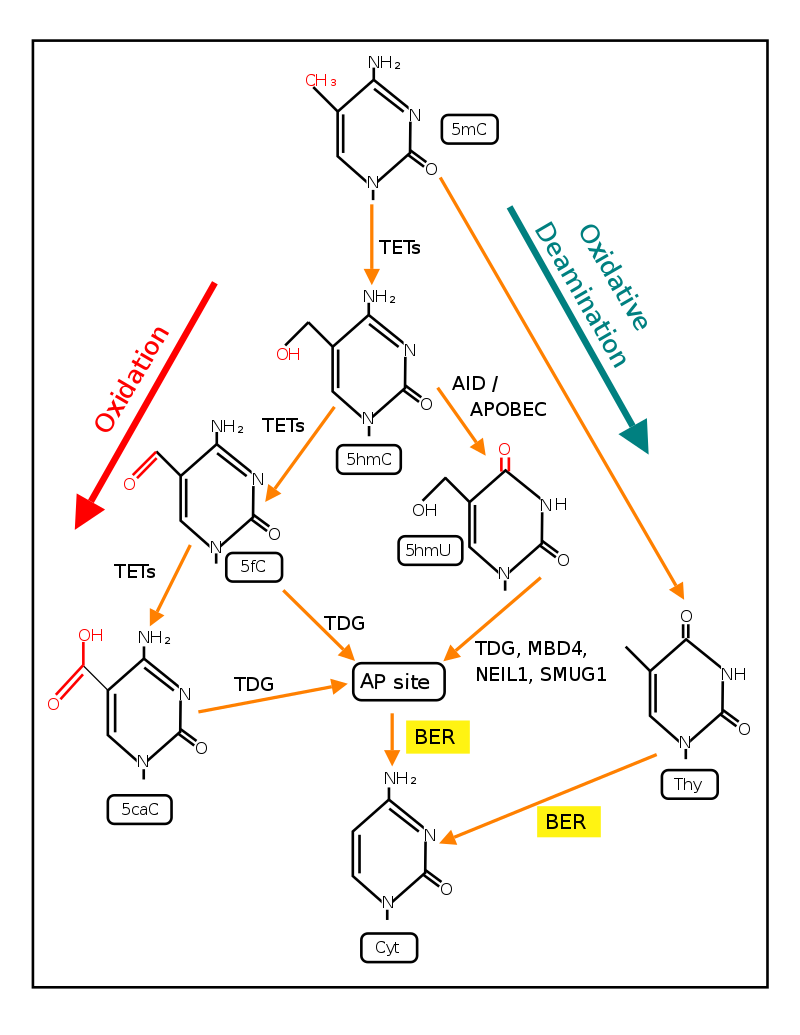

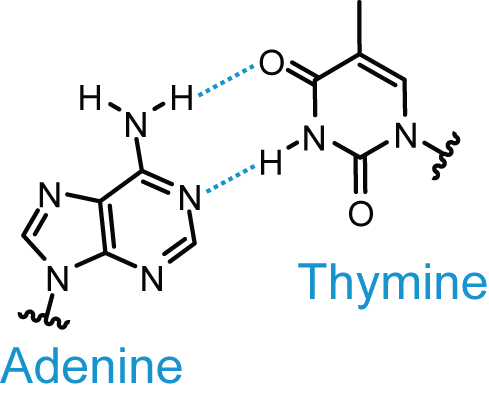
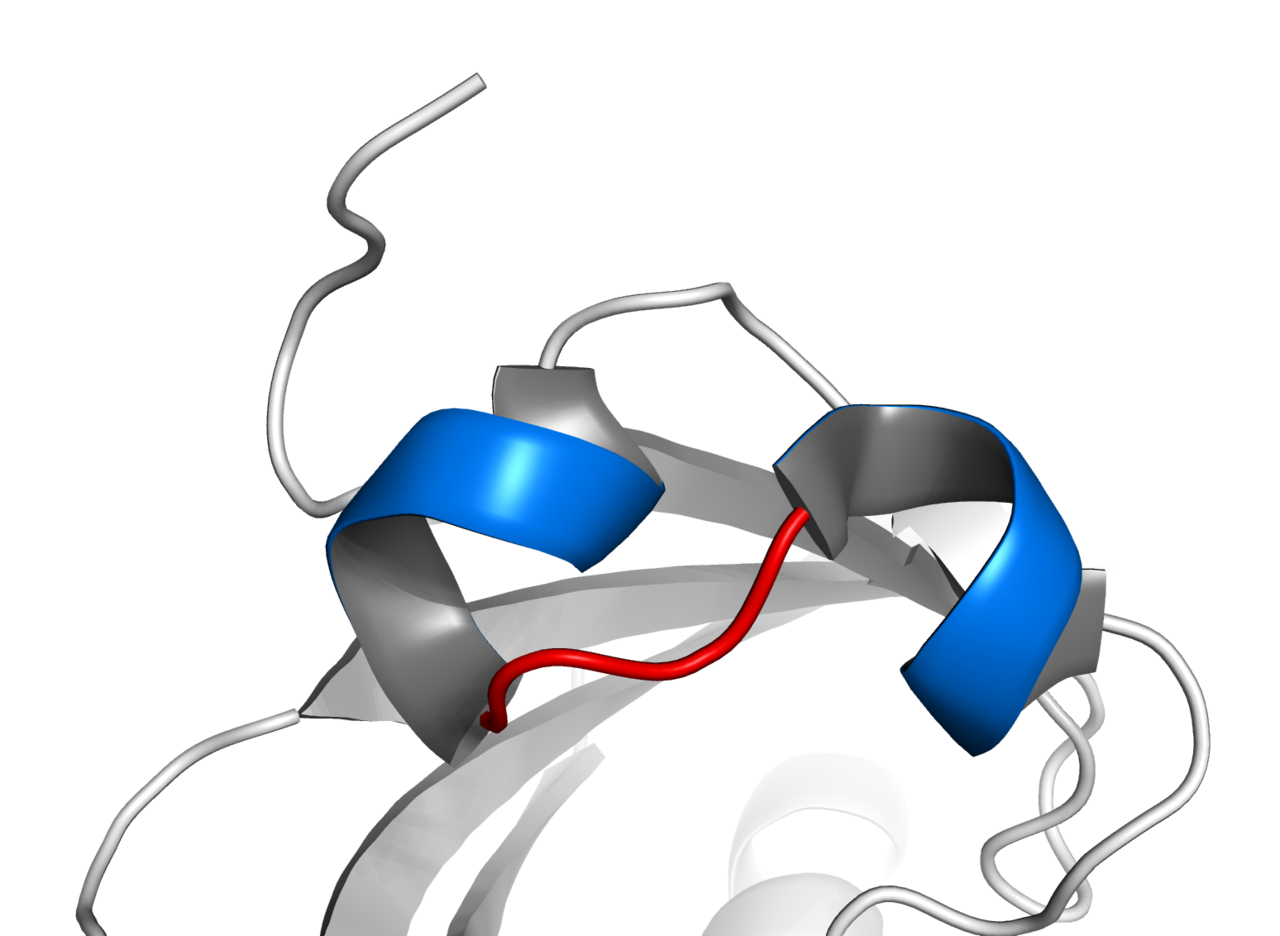
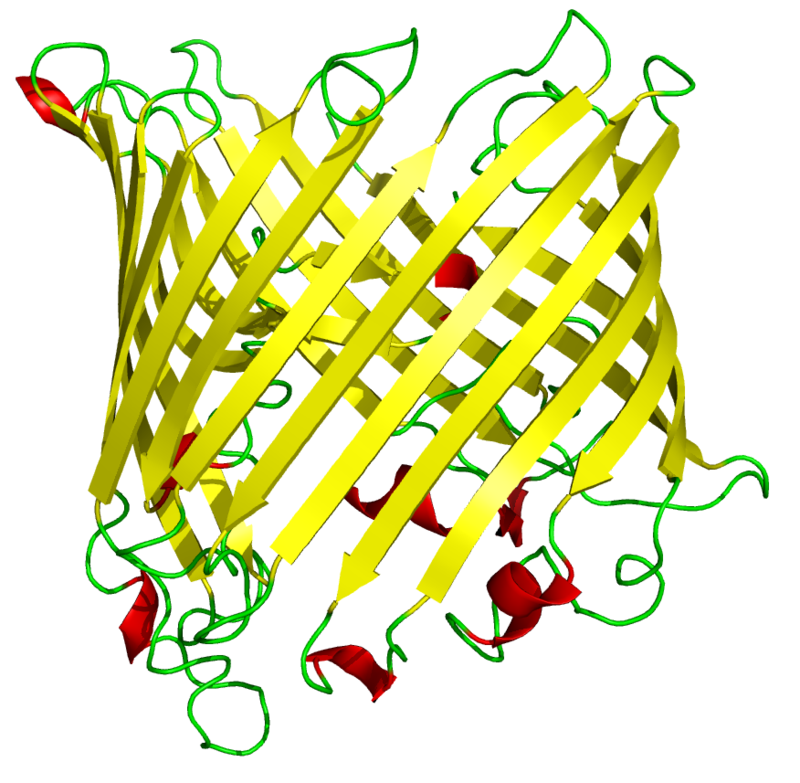
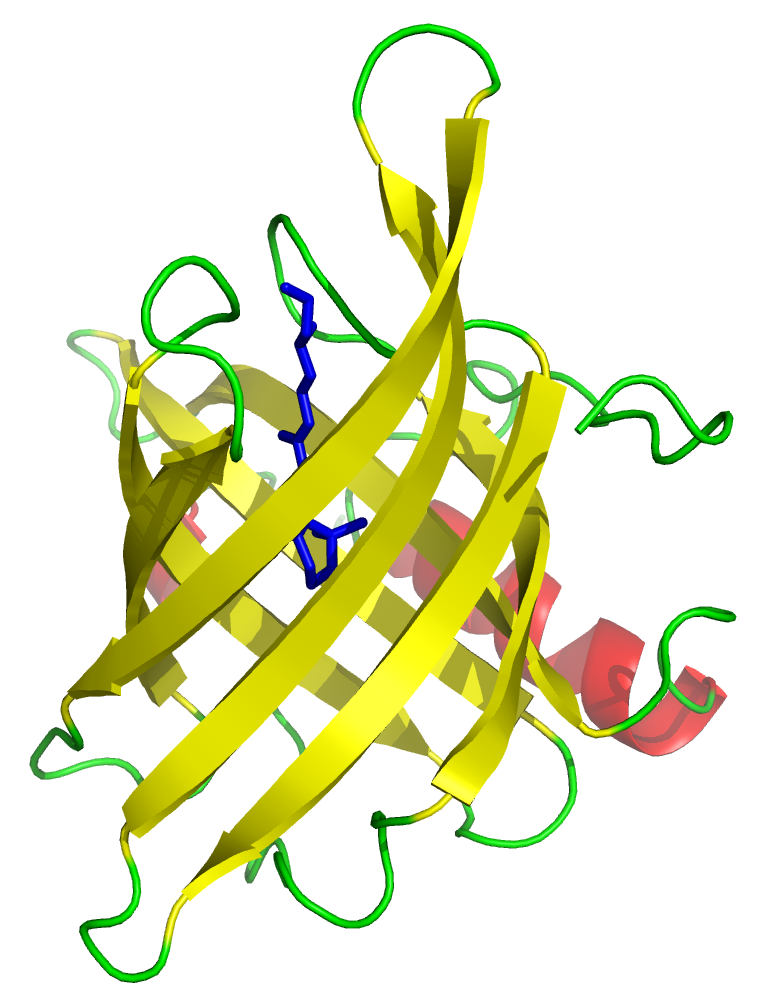
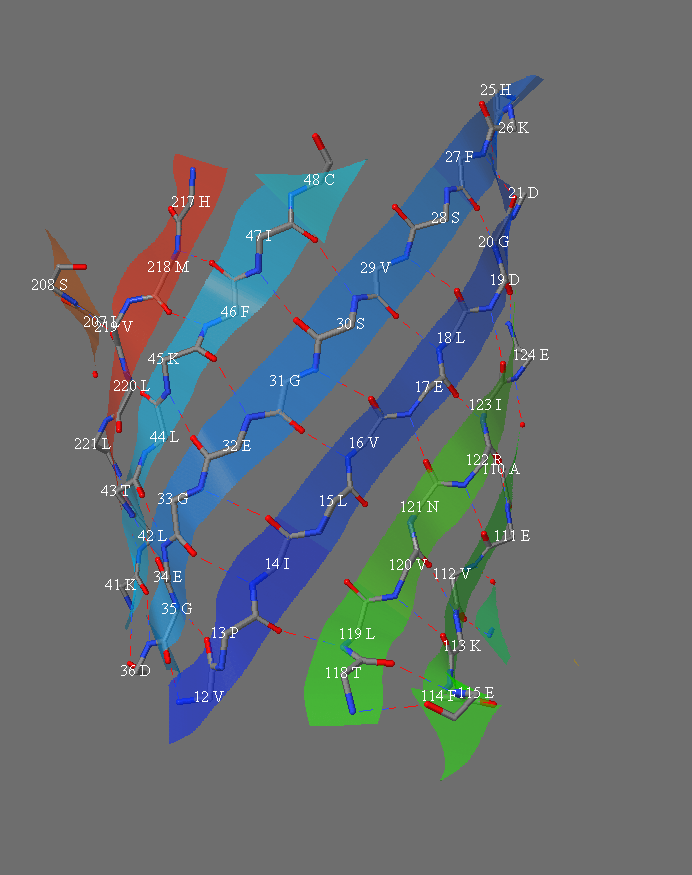
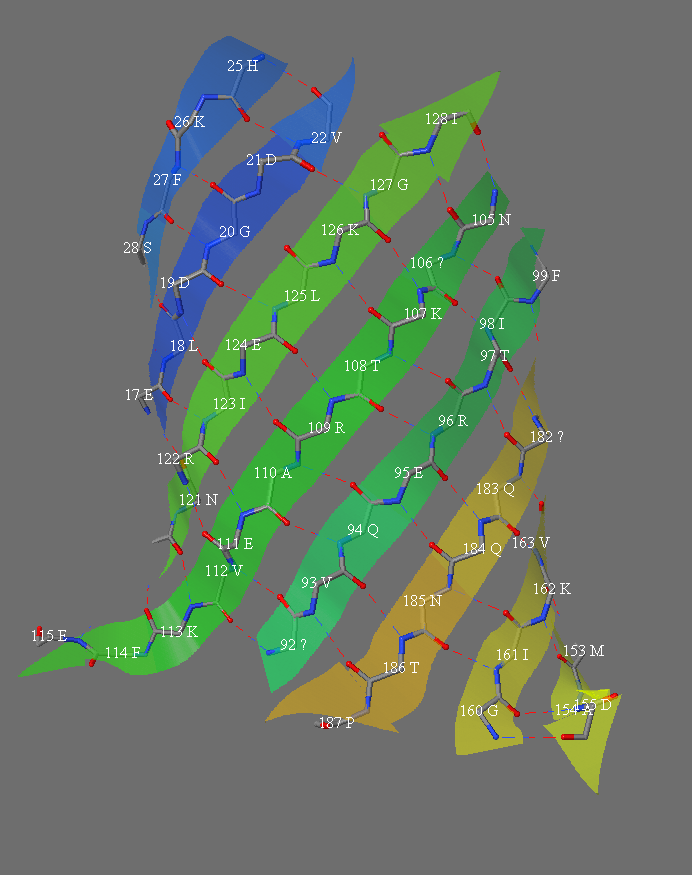
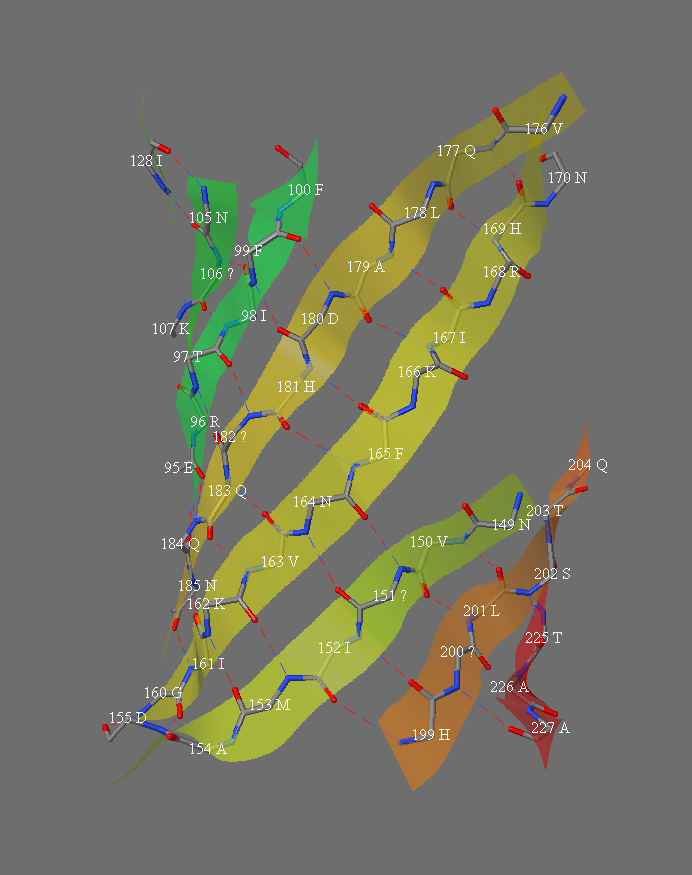
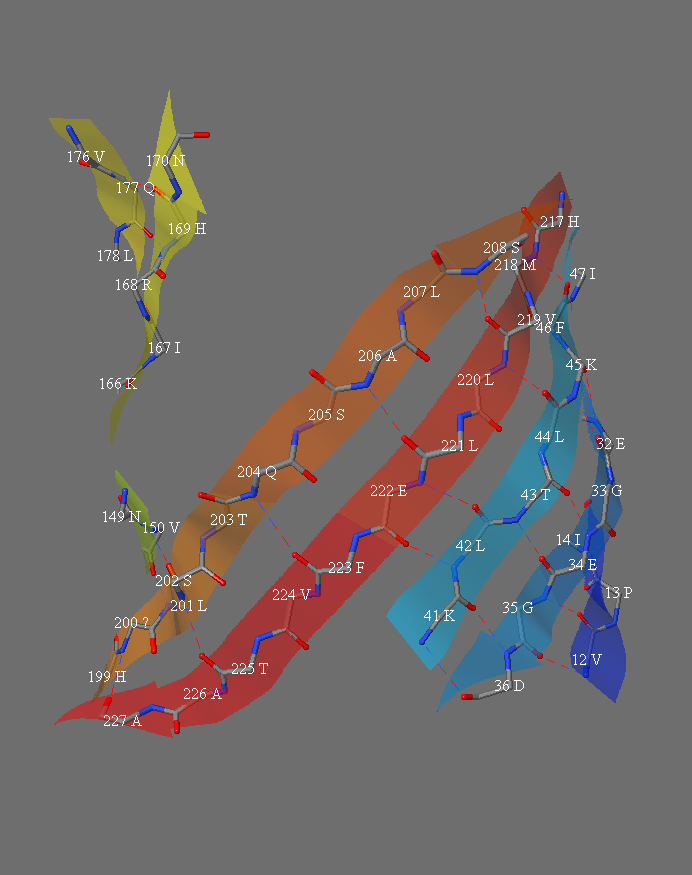
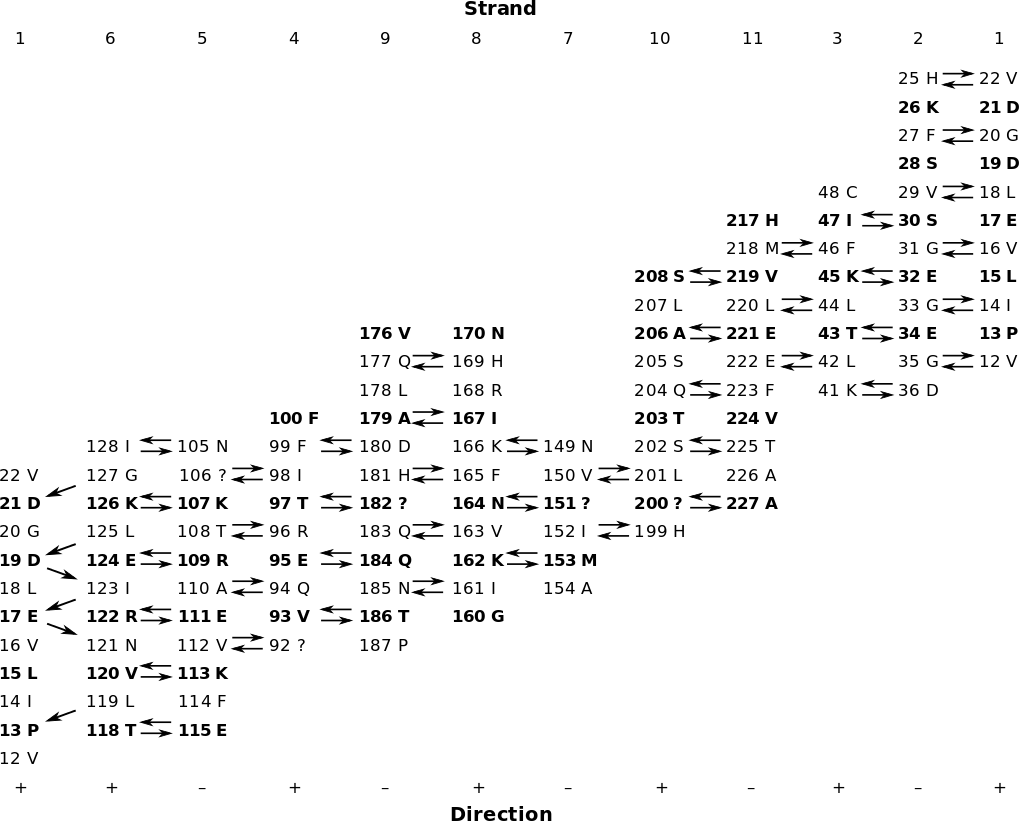
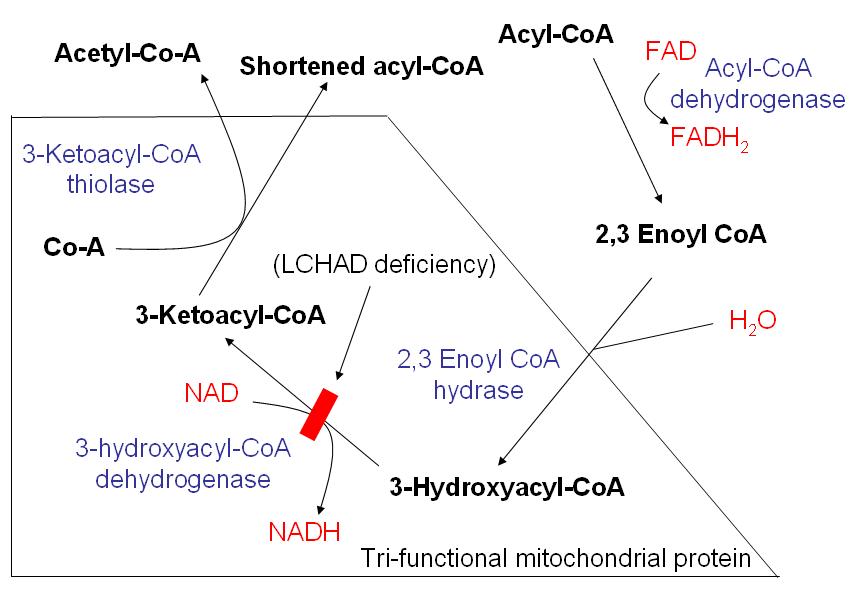
.png)
.png)